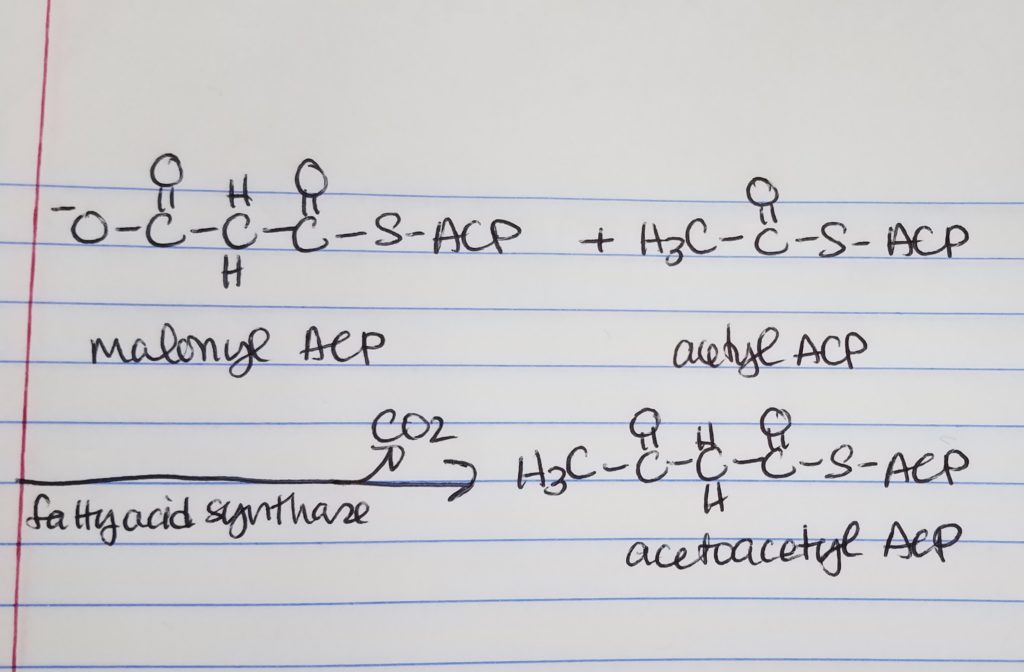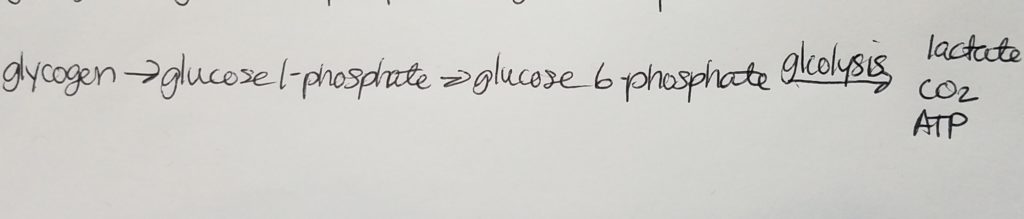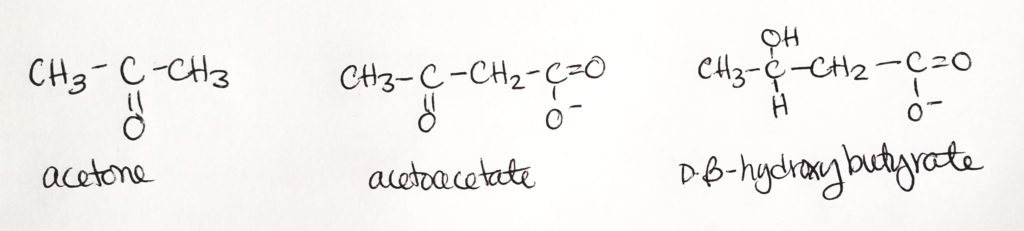WHO announced the official disease name as COVID-19 caused by the newly named virus SARS-CoV-2 to replace the former “2019-nCoV” (International Committee on Taxonomy of Viruses).
Although people don’t like to say it, COVID-19 is a pandemic. It’s been shown to appear on pockets and demographics that do not seem to have any direct contact/relation to China.
Origins & Genome
2019-nCoV was first found & recognized in Wuhan, China.
Genetically closest to SARS-CoV (shared 79.5% similarity) in the Betacoronaviruses (Nidovirales, Coronaviridae, Coronavirinae, Betacoronavirus, Sarbecovirus), and also shares similiarities with bat SARS-like variants, possibly BatCoV RaTG13 (96.2%).
Virus was thought to have crossed over to humans from bats.
The report trying to link HIV to 2019-nCoV was erroneous.
Reports of 2019-nCoV originating from snakes were erroneous.
Produces acute respiratory illnesses, fever, cough, difficulty breathing/shortness of breath.
2019-nCoV targets the angiotensin converting enzyme 2 (ACE2) receptor.
Incubation ranges between 2-14 days. Some say up to 20 days.
Use standard airborne disease precautions.
The severity of symptoms is variable.
Babies and children have mostly been spared.
There have been some cases of people being re-infected, but that is not too clear.
Testing has been somewhat unclear at this point.
Transmission
Human-to-human spread up to approximately 6 feet distance (CDC, 02.05.2020) via airborne droplets from in infected person (e.g. sneezing, coughing, etc.).
High sputum viral load.
The virus may persist on surfaces but only for a relatively “short time”.
The virus has been found in feces, but the main transmission method is still in droplets–airborne.
People who carry the virus but don’t show symptoms can still spread the disease, asymptomatic spreading.
Hand hygiene is important. As taught in nursing school: use warm water; use antibacterial soap to vigorously scrub front-back-nails of hand for at the very least 20 secs. DO NOT TOUCH the faucet or anything else. Dry your hands and use the paper towel to shut off the water. If your paper towel dispenser is not automatic/motion-controlled, then before you wash your hands pull some paper towel down so that you can avoid touching the dispenser after your hand wash. https://www.cdc.gov/handwashing/when-how-handwashing.html
Centers for Disease Control (CDC), & National Center for Immunization and Respiratory Diseases (NCIRD), Division of Viral Diseases. (2020, January 31). Transmission of Novel Coronavirus (2019-nCoV). Retrieved February 5, 2020, from https://www.cdc.gov/coronavirus/2019-ncov/about/transmission.html
Cohen, J. (2020, January 31). Mining coronavirus genomes for clues to the outbreak’s origins. Retrieved February 5, 2020, from https://www.sciencemag.org/news/2020/01/mining-coronavirus-genomes-clues-outbreak-s-origins
European Centre for Disease Prevention and Control (ECDC). (2020, January 31). Disease background of 2019-nCoV. Retrieved from https://www.ecdc.europa.eu/en/2019-ncov-background-disease
Greens, K. (2020, February 4). Report of asymptomatic transmission of 2019-nCoV inaccurate. Retrieved from https://www.the-scientist.com/news-opinion/report-of-asymptomatic-transmission-of-2019-ncov-inaccurate-67060
Kupferschmidt, K. (2020, February 3). Study claiming new coronavirus can be transmitted by people without symptoms was flawed. Retrieved from https://www.sciencemag.org/news/2020/02/paper-non-symptomatic-patient-transmitting-coronavirus-wrong
The New England Journal of Medicine (NEJM). (2020, January 30). Transmission of 2019-nCoV infection from an asymptomatic contact in Germany. Retrieved from https://www.nejm.org/doi/full/10.1056/NEJMc2001468
Paraskevis, D., Kostaki, E. G., Magiorkinis, G., Panayiotakopoulos, G., Sourvinos, G., & Tsiodras, S. (2020). Full-genome evolutionary analysis of the novel corona virus (2019-nCoV) rejects the hypothesis of emergence as a result of a recent recombination event. Infection, Genetics and Evolution, 104212.
Robertson, D. L. (2020, January 26). nCoV’s relationship to bat coronaviruses & recombination signals (no snakes) – no evidence the 2019-nCoV lineage is recombinant. Retrieved February 5, 2020, from https://virological.org/t/ncovs-relationship-to-bat-coronaviruses-recombination-signals-no-snakes-no-evidence-the-2019-ncov-lineage-is-recombinant/331
Coronaviruses are responsible for one-third of the common colds and respiratory illnesses (ranging from mild to severe) among humans like upper respiratory tract infections (URTIs) and lower respiratory tract infections (LRTIs bronchitis, pneumonia, severe acute respiratory syndrome) (Burrell, Howard, & Murphy, 2016; Li et al., 2019; Shoeman & Fielding, 2019). These viruses are higly adaptable and prone to mutation (selective pressure, environment).
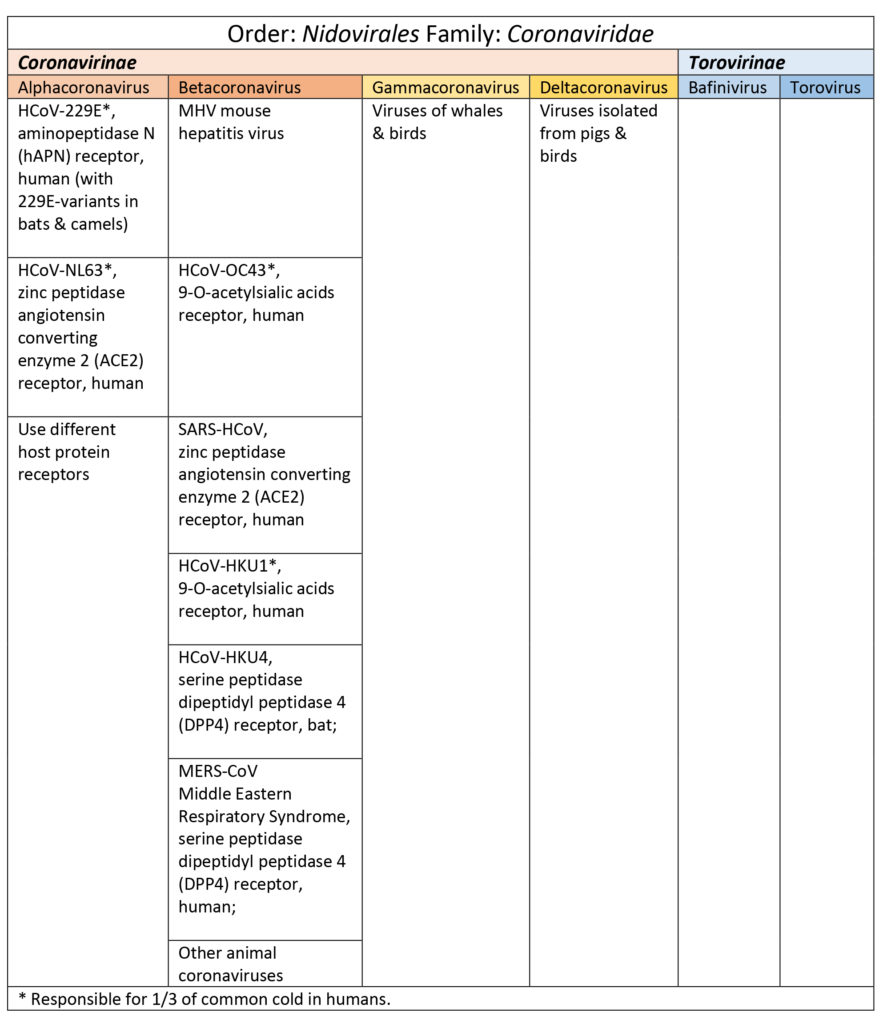
Coronaviruses belong to the order Nidovirales and family Coronaviridae. There are two subfamiles: Coronavirinae (spherical) and Torovirinae (disc, bean or rod-shaped and pertain mostly to horses, cattle, pigs, cats, and goats illnesses). Coronaviruses get their name from their unique from their “fringe-like” envelope with glycoproteins sticking out looking like a crown or crown-of-thorns (Burrell et al., 2016; Shoeman & Fielding, 2019).
Coronavirinae are subdivided into four genus categories: alpha, beta, gamma (whales, birds), & delta (pigs & birds). Coronaviruses in the alpha and beta categories viruses that have affected humans are HCoV-229E, HCoV-NL63, HCoV-OC43, SARS-HCoV, HCoV-HKU1, and MERS-CoV (Burrell et al., 2016; Shoeman & Fielding, 2019). See Table 1. SARS, SARS-like, and MERS-CoV share a good percentage of their genome with bat coronaviruses (Burrell et al., 2016; Shoeman & Fielding, 2019).
Table 1
Structural Proteins
Coronaviruses have 4 key structural proteins S, M, N, and E. S (spike) protein is a large glycoprotein responsible for forming the peplomers (glycoprotein spikes which will selectively bind to certain receptors) of the envelope. M is a transmembrane glycoprotein. N is a phosphorylated nucleocapsid. Additionally, E is a envelope protein and some species of betacoronaviruses also have protein HE (hemagglutination and esterase functions) (Burrell et al., 2016; Shoeman & Fielding, 2019; Tok & Tatar, 2017). Interestingly, not all four key structural proteins are required for producing a viable virion which suggests there may be some redundancy in the genome (Shoeman & Fielding, 2019). The S, M, N, and E proteins also participate in viral replication.
Viral Genome
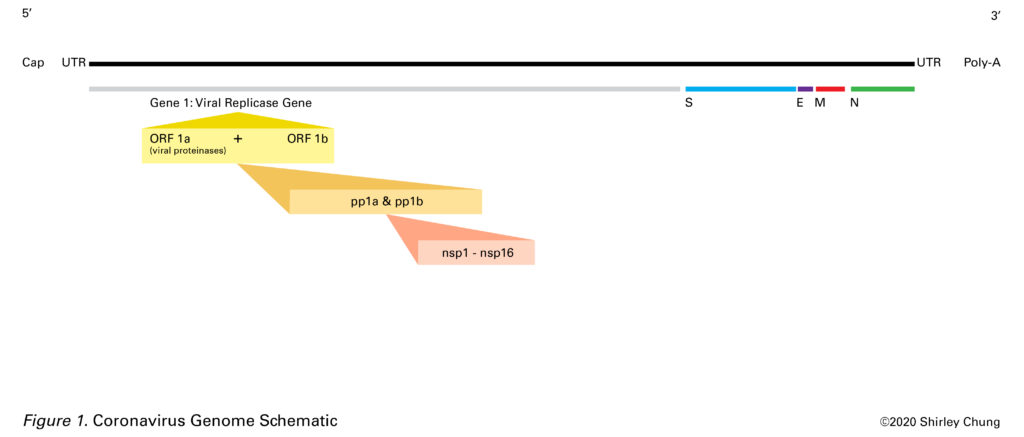
Coronaviruses have a single strand positive-sense RNA (+ssRNA) 26-32 kilobases (kb) long (Burrell et al., 2016; Shoeman & Fielding, 2019). This +ssRNA is of the same sense as host mRNA which allows the virus to harness the host cell’s machinery. The 5′ end (has untranslated sequence, UTR, of 65-78 nucleotides or leader RNA) is capped and the 3′ end has 200-300 UTR nucleotide sequence plus the poly-A tail (Burrell et al., 2016; Shoeman & Fielding, 2019). The 5′ cap is a way for the virus to disguise its genetic material to make it similar to host mRNA in order to use the host’s “machinery” (Picard-Jean, 2013).Nested mRNAs all share the same 5′ end sequence (Burrell et al., 2016; Shoeman & Fielding, 2019). Untranslated regions (UTRs) help regulate replication and transcription.
There are 7-14 open reading frames (ORFs) which are a sequence of codons that begin with a start codon and end with a stop codon (Burrell et al., 2016). These ORFs are interspersed within the genome.
Starting at the 5′ end (plus UTR), gene 1 (20-22 kilobases long) is about two-thirds of the entire RNA length. The spike (S) protein gene comes next followed by the E (envelope) protein gene, M (transmembrane) protein gene, the N (nucleocapsid) gene, another UTR sequence plus poly-A tail at the 3′ end (Burrell et al., 2016; Li, 2016; Shoeman & Fielding, 2019). Other ORF proteins, the HE glycoprotein gene, and accessory protein genes are interspersed amongst the aforementioned major segments (Burrell et al., 2016; Shoeman & Fielding, 2019; Tok & Tatar, 2017). Burrell et al. (2016) noted that ORFs may code for accessory proteins that may account for variability and novel species. The SARS-CoV RNA contains smaller ORFs at the 3′ end that are unique to SARS-CoV (Burrell et al., 2016). Accessory proteins may also contribute to viral hardiness.
The Viral Replicase Gene (aka Gene 1)
Gene 1 contains overlapping ORFs 1a and 1b (Burrell et al., 2016). Together, ORFs 1a and 1b constitute the viral replicase gene (gene 1) and encode for two large polyproteins (pp1a and pp1b, proteins that are covalently conjoined) (Nakagawa, Lokugamage, & Makino, 2016). In general, replicase is an enzyme that catalyzes the production of a complementary RNA strand based off of an RNA template. Proteases help cleave out 15-16 nonstructural proteins (nsp1-nsp16) from the two polyproteins to be used in the viral lifecycle (Nakagawa et al., 2016). Nsp 2-nsp16 are critical to viral RNA transcription and replication (Nakagawa et al., 2016).
The S (Spike) Protein
The S glycoprotein is important as it plays a major role in the first step towards creating viral progeny. The spike determines if a virus can fuse with a host and enter. Successful fusion is receptor-dependent. S is a clove-shaped homotrimer (protein made of 3 identical subunits) (Li, 2016). The S protein is also responsible for possible multiple cell fusions between the infected and adjacent cells, syncytia (Shoeman & Fielding, 2019).
There are three classes of fusion proteins based on the structure of their fusion subunits: class I, mostly alpha-helical; class II mostly beta-structures; class III both alpha-helical and beta-structures (Harrison, 2012; White & Whittaker, 2016). Coronaviruses S protein is class I (White & Whittaker, 2016). Other class I viruses include some forms of influenza, human immunodeficiency virus (HIV), and Ebola (Li, 2017).
The spike has regions: large ectodomain (the part that sticks out into the extracellular space where upon contact may initiate signal transduction); single-pass (crosses membrane only once) transmembrane anchor (TM1); and intracellular tail (Li, 2016). The ectodomain contains S1 (trimeric head) and S2 (trimeric stalk) (Li, 2017).
For many coronaviruses, host cell enzymes (proteases) break down S into subunits S1 and S2 (Tortorici et al., 2019). Before fusion occurs, S1 and S2 are non-covalently held together. The N-terminal S1 subunit is made of four areas A, B, C, and D. A and B are the receptor-binding areas in coronaviruses (Tortorici et al., 2019). The C-terminal S2 subunit is where the “fusion machinery” is located allowing for S2 to fuse the viral and host membranes (Li, 2016; Tortorici et al., 2019). Upon entry into the host, S2 is cleaved again at S2′ (this happens for all coronaviruses) and scientists think it may be a step that activates the protein for membrane fusion as it produces irreversible conformational changes (Tortorici et al., 2019).
Post-fusion, the pre-fusion three heads of S2 become a six-bundled helical structure with fusion peptides sticking out (Li, 2017).
The N (Nucleocapsid) Protein
N is the only protein responsible for phosphorylated helical nucleocapsid (“shell” enclosing the genome) (Shoeman & Fielding, 2019). The N protein is located near the endoplasmic reticulum (ER) and Golgi complex area. Expression of the N gene was found to coincide with the increased production of virus-like particles (VLPs), and scientists believe that N may contribute towards producing whole and viable virions (Shoeman & Fielding, 2019).
The M (Transmembrane) Protein
The M glycoprotein has three transmembrane areas and influences the shape of the envelope (Shoeman & Fielding, 2019; Tok & Tater, 2017). In the Golgi complex, a carbohydrate unit is attached to the M protein (glycosylation which is important for protein folding) which contributes to the protein’s ability to bind at receptor sites (Tok & Tatar, 2017).
M may also have an “organizational” role as it interacts with the other structural proteins (Shoeman & Fielding, 2019). M seemed to interact with S protein to “corral” or aggregate S in the ER-Golgi intermediate compartment (ERGIC, mediate transport between the ER and Golgi complex) thus allowing for packaging into new virions (Shoeman & Fielding, 2019). M interacting with N increased nucleocapsid stability (Shoeman & Fielding, 2019). M and E protein interaction contributed to the maintenance of the envelope, the production and release of VLPs (Shoeman & Fielding, 2019).
The E (Envelope) Protein
E proteins (short integral membrane proteins 76-109 amino acids long) are the smallest structural proteins and the least understood. At the hydrophilic N-terminal, E has 7-12 amino acids followed by a transmembrane domain (TMD) 25 amino acids long, and ending with a long hydrophilic C-terminal (Shoeman & Fielding). Surprisingly, E protein was not found to be abundant embedded in the viral envelope which suggested that E may serve in other capacities around the ER, Golgi, and ERGIC locations (Shoeman & Fielding, 2019). E proliferation was found inside the host (near ER, Golgi complex, ERGIC) during viral replication, and the lack of E protein seemed to have deleterious effects on viral progeny (Shoeman & Fielding, 2019).
An unique feature of coronaviruses is that they bud into the ERGIC where they get packaged into their envelope (Shoeman & Fielding, 2019). In contrast, other viruses bud only from the inside face of the plasma membrane. E protein was found to play a role in scission to complete the release of viral progeny.
Transmembrane areas (TMDs) are important for the viral ability to fuse with a host (Webb, Smith, Fried, & Dutch, 2018). Viroporins are a type of transmembrane protein. Viroporins are small viral pH-sensitive pore-inducing proteins (60-120 amino acids long, mostly hydrophobic) that can create passageways (hydrophilic pores selective for H+, K+, Na+, Ca2+ but also able to transport anions) for the virus to utilize during different reproductive activities of its life cycle (Schoeman & Fielding, 2019). The lack of viroporins was found to mediate viral pathogenicity. Targeting a virus’s viroporin may be one way to interrupt it’s activities.
The HE (Hemagglutination and Esterase) Protein
The HE protein (found in some betacoronaviruses) is associated with the viral envelope. HE acts like hemagglutinin (HA) and binds to sialic acid (Sia) which is a derivative of neuraminic acids, 9-carbon backbone acidic sugars (N-acetylneuraminic acid) (Chemspider, n.d.; Langereis, Zeng, Heesters, Huizinga, & De Groot, 2012; Mora-Díaz, Piñeyro, Houston, Zimmerman, & Giménez-Lirola, 2019; Zanin, Baviskar, Webster, & Webby, 2016). Sia is sometimes used synonymously as N-acetylneuraminic acid. Sia is important in maintaining a mucous defense. HA binds to Sia of mucins and disrupts this mucous defense system (Mora-Díaz et al., 2019; Zanin et al., 2016).
Clinical
Coronaviruses favor and tend to first replicate in the respiratory or intestinal tracts (Burrell et al., 2016). They may be stable for some time outside of the human body on environmental/object surfaces (fomites) (Burrell et al., 2016). Coronaviruses may also be found in stools. Mouse hepatitis virus (MHV) is a type of betacoronavirus that can be found not only in the respiratory/intestinal tracts but also causing liver and central nervous system infections (Burrell et al., 2016). The neurological effects of MHV have been studied extensively due to its similarity to multiple sclerosis (MS) in humans (Burrell et al., 2016). Cross-immunity between different coronaviruses does not seem likely (Burrell et al., 2016). Coronaviruses are difficult to detect as an infected person may remain asymptomatic. One challenge in studying coronaviruses is that they are difficult to grow in vitro.
Closing
In order to take a step forward to try understand 2019-nCoV, it was necessary to take a step backward and try understand some of the general features of the coronaviruses. Moving forward, the next step is to learn about some of the unique features of 2019-nCoV. Undoubtedly, such knowledge at this nascent stage of viral outbreak remains fluid and dynamic.
References
Burrell, C. J., Howard, C. R., & Murphy, F. A. (2016). Fenner and White’s Medical Virology, 5.
Chemspider. (n.d.). N-Acetylneuraminic acid | C11H19NO9. Retrieved February 4, 2020, from https://www.chemspider.com/Chemical-Structure.10292217.html
Harrison, S., & Harvard Howard Hughes Medical Institute (HHMI). (2012a, March 24). Part 2: Viral membrane fusion [Video]. Retrieved from https://youtu.be/qcepGvFUM38
Harrison, S., & Harvard Howard Hughes Medical Institute (HHMI). (2013b, November 1). Class 1 viral fusion proteins [Video]. Retrieved from https://youtu.be/FcX9mD8rvYw
Langereis, M. A., Zeng, Q., Heesters, B., Huizinga, E. G., & De Groot, R. J. (2012). The murine coronavirus hemagglutinin-esterase receptor-binding site: a major shift in ligand specificity through modest changes in architecture. PLoS pathogens, 8(1).
Li F. (2016). Structure, Function, and Evolution of Coronavirus Spike Proteins. Annual review of virology, 3(1), 237–261. doi:10.1146/annurev-virology-110615-042301
Li, Z., Tomlinson, A. C., Wong, A. H., Zhou, D., Desforges, M., Talbot, P. J., … & Rini, J. M. (2019). The human coronavirus HCoV-229E S-protein structure and receptor binding. eLife, 8.
Mora-Díaz, J. C., Piñeyro, P. E., Houston, E., Zimmerman, J., & Giménez-Lirola, L. G. (2019). Porcine Hemagglutinating Encephalomyelitis Virus: A Review. Frontiers in veterinary science, 6.
Nakagawa, K., Lokugamage, K. G., & Makino, S. (2016). Viral and cellular mRNA translation in coronavirus-infected cells. In Advances in virus research (Vol. 96, pp. 165-192). Academic Press.
National Human Genome Research Institute (NHGRI). (n.d.). Open Reading Frame. Retrieved from https://www.genome.gov/genetics-glossary/Open-Reading-Frame
Picard-Jean, F., Tremblay-Létourneau, M., Serra, E., Dimech, C., Schulz, H., Anselin, M., … & Bisaillon, M. (2013). RNA 5′-end maturation: a crucial step in the replication of viral genomes. Current Issues in Molecular Virology: Viral Genetics and Biotechnological Applications, 27.
Schoeman, D., & Fielding, B. C. (2019). Coronavirus envelope protein: current knowledge. Virology journal, 16(1), 69.
Tok, T. T., & Tatar, G. (2017). Structures and Functions of Coronavirus Proteins: Molecular Modeling of Viral Nucleoprotein.
Tortorici, M. A., Walls, A. C., Lang, Y., Wang, C., Li, Z., Koerhuis, D., … & Veesler, D. (2019). Structural basis for human coronavirus attachment to sialic acid receptors. Nature structural & molecular biology, 26(6), 481-489.
University of Washington Health Sciences/UW Medicine. (2016, February 26). Electron microscopy captures snapshot of structure coronaviruses use to enter cells: Atomic model suggests vaccine strategies against deadly pandemic viruses such as SARS-CoV and MERS-CoV. ScienceDaily. Retrieved January 31, 2020 from www.sciencedaily.com/releases/2016/02/160226173209.htm
Webb, S. R., Smith, S. E., Fried, M. G., & Dutch, R. E. (2018). Transmembrane Domains of Highly Pathogenic Viral Fusion Proteins Exhibit Trimeric Association In Vitro. mSphere, 3(2), e00047-18.
White, J. M., & Whittaker, G. R. (2016). Fusion of enveloped viruses in endosomes. Traffic, 17(6), 593-614.
Zanin, M., Baviskar, P., Webster, R., & Webby, R. (2016). The interaction between respiratory pathogens and mucus. Cell host & microbe, 19(2), 159-168.
From our previous post on R “nought” (the basic reproduction number), R0 is a best estimation and defined as: “the average number of secondary infections generated by the first infectious individual in a population of completely susceptible individuals” (CIDD, 2014a; CIDD, 2014b).
If R0>1, then the outbreak is likely to continue; if R0<1, then the outbreak has a better potential for being contained (Delamater et al. 2019). Anticipated outbreak/epidemic size is commonly based on R0 as is the estimation of the number of people needing to be vaccinated (Delamater et al., 2019).
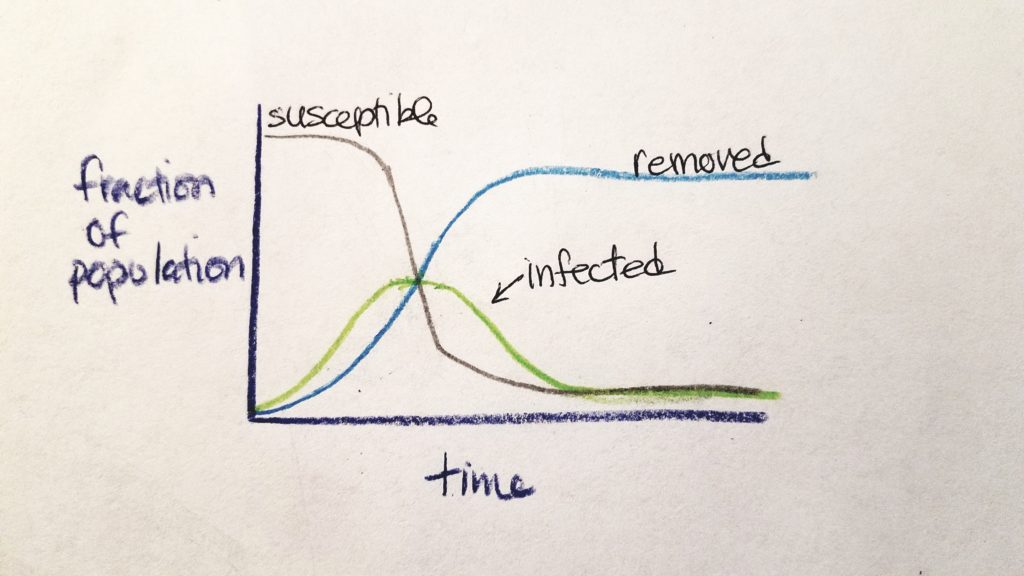
R0 values are calculated early at the onset of an outbreak. As time goes on, the nature and numbers of the outbreak change. At the beginning, most people are susceptible and the rate of potential transmission is exponentially great. As time goes on, people are either susceptible (S), infected (I), or removed from the chain of infection as non-susceptible (R) (either they are immune and regain health or they are dead) (CIDD, 2014b). The rate of susceptible people and infected people decreases as the rate of removed people increases.
This was explained by CIDD (2014b) as a “stylized” model called SIR Compartmental Framework (S=susceptible, I=infected, R=removed).
The speed of increase of infected individuals depends on R0 and the infectious period–higher R0 and shorter infectious period models a more prolific spread of the disease (CIDD, 2014b). As time goes on and assuming that more individuals are not added into the original population, the number of susceptible individuals decrease (either they died or regained their health).
The effective reproductive number (RE) is the average number of new infections later in the epidemic. RE(t) is defined as a function of time (t): the average number of secondary infections caused by a newly infected individual at time, t (Chirombo, Diggle, Terlouw, & Read, 2018).
RE is a product of R0 and the fraction of susceptible population: RE = R0 x fraction_of_susceptible_population (CIDD, 2014b). If RE < 1, the epidemic is self-limiting and said to be under control due to countermeasures (CIDD, 2014b; Chirombo et al., 2018). When the proportion of susceptible individuals is less than 1/R0, we call this “the point at which the population reaches herd immunity” (CIDD, 2014b).
Herd immunity is best defined by Wikipedia (2002) as: “a form of indirect protection from infectious disease that occurs when a large percentage of a population has become immune to an infection, thereby providing a measure of protection for individuals who are not immune”. Other definitions mention vaccination, but Wikipedia’s definition is more generalized (and most applicable) while retaining the same meaning.
As of January 26th, 2020 Zhang & Wang (2020) estimated RE for 2019-nCoV to range between 3.3-5.5 which concur with other studies (Cao et al., 2020).
Cao, Z., Zhang, Q., Lu, X., Pfeiffer, D., Jia, Z., Song, H., & Zeng, D. (2020). Estimating the effective reproduction number of the 2019-nCoV in China. medRxiv. https://doi.org/10.1101/2020.01.27.20018952
Center for Infectious Disease Dynamics (CIDD). (2014a, March 19). Week 1 Video 5: Reproductive Number [Video]. https://youtu.be/ju26rvzfFg4
Center for Infectious Disease Dynamics (CIDD). (2014b, March 19). Week 1 Video 6: Epidemic Curve [Video]. https://youtu.be/sSLfrSSmJZM
Chirombo, J., Diggle, P. J., Terlouw, D. J., & Read, J. M. (2018). Estimation of spatially varying effective reproduction numbers for infectious disease epidemics. Modelling spatial processes of infectious diseases, 39.
Delamater, P. L., Street, E. J., Leslie, T. F., Yang, Y. T., & Jacobsen, K. H. (2019). Complexity of the basic reproduction number (R0). Emerging infectious diseases, 25(1), 1.
Wikipedia. (2002, September 18). Herd immunity. https://en.wikipedia.org/wiki/Herd_immunity
Zhang, C., & Wang, M. (2020). Origin time and epidemic dynamics of the 2019 novel coronavirus. bioRxiv.
Many factors contribute to how disease is spread including (but not limited to): the type of pathogenic microbe; the lifespan of the microbe; any special features of the microbe; the disease vector (and its location, movement, lifespan, lifestyle characteristics/habits); the location/weather/natural barriers/migration patterns; the age/health/nutrition profile/lifestyle/habits of the infected person and his/her location plus the number of people that the infected person may encounter daily; the people in daily contact with the infected person and these people’s age/health/nutrition profile/lifestyle etc.
These details are elements of the epidemiologic triad (agent, host, and environmental factors) (Delamater, Street, Leslie, Yang, & Jacobsen, 2019). In epidemiology, R0 is used to estimate how infectious a pathogen might be (especially novel pathogens and potential outbreaks).
R “nought” or R0 is the basic reproduction number is defined as “the average number of secondary infections generated by the first infectious individual in a population of completely susceptible individuals” (CIDD, 2014a; CIDD, 2014b).
For example, consider person0 who is infected. How long has that person0 been infected? The longer person0 has been infected, the more opportunity there is for person0 to be in contact with more people and potentially infect them. The length of infection (L) is a variable that can increase the value of R0 (CIDD, 2014a; Cintrón-Arias, 2015).
Susceptible hosts (S) are (in this case we are talking about) other people who can potentially catch the disease from person0 (CIDD, 2014a; Cintrón-Arias, 2015 ). If person0 knows a lot of people and is in contact with a lot of people, then the number of susceptible hosts (S) is larger–increase the number of potentially infected people (R0 increases). Also, consider where person0 is living. If person0 is living in New York City where the population density is very high, S can also increase. This may continue on exponentially (CIDD, 2014a; CIDD, 2014b).
R0 also depends on transmissability–how transmissable is a pathogen. What affects transmissability? The properties of the pathogen and the population being studied affect transmissability (B, “beta”). The rate of potentially transmissable contacts (PT) and the likelihood of a successful transmission (ST, the infected person gets sick) are factors in T (CIDDa, 2014).
ST depends on the characteristics of the pathogen. Some pathogens are very hardy and prolific. For example, you can catch the pathogen just by being in the same room as the sick person. Some pathogens are very fragile and “finicky” making them more difficult to be successfully transmitted–they have many more environmental requirements in order for them to be viable.
Potentially transmissable contacts (PT) is dependent on the characteristics of the population. More susceptible people include those who are very young/elderly, people lacking good nutrition, people who already have other health problems, etc.
R0 is a function of S, L, and B. R0 may be a single value or a low-to-high range. Remember that R0 is a “best guess” for the current situation–it is not definitive. In the case of a novel pathogen, R0 must be modeled off of knowledge of past outbreaks with known pathogens. Complex math, artificial intelligence, dynamic computation, and scientists from many different fields contribute to such work.
If R0>1, then the outbreak is likely to continue; if R0<1, then the outbreak has a better potential for being contained (Delamater et al. 2019). Anticipated outbreak/epidemic size is commonly based on R0 as is the estimation of the number of people needing to be vaccinated (Delamater et al., 2019).
Using available data for 2019-nCoV through January 21st, 2020, Read, Bridgen, Cummings, Ho, and Jacobsen (2019) estimated R0 (model based on human-human transmission, omitting zoonotic transmission) to be 3.8 (95% confidence interval, 3.6 and 4.0) implicating that 72-75% of transmissions must be prevented/controlled in order to stop the increase. Read et al. (2019) also estimated that only 5.1% (95% confidence interval, 4.8-5.5) of the infections in Wuhan have actually been identified/confirmed. It was very likely that the information and statistics released to the media (especially from the Chinese government) were under-reported. Predicted numbers were closer to 191,529 infections by February 4th, 2020 (Read et al., 2019). From rough estimates, R0 for 2019-nCoV are significantly greater than the R0 for MERS-CoV, but closer to the R0 for SARS (Read et al., 2019).
Using Virus Host Prediction (VHP), Zhu et al. (2020) found the infectivity pattern of 2019-nCoV to be more similar to Bat SARS-like coronavirus and mink coronavirus. The Huanan seafood and wet market included sales of produce, mean, and live animals crammed together in stalls (Woodward, 2020; Zhu et al., 2020).
References
Center for Infectious Disease Dynamics (CIDD). (2014a, March 19). Week 1 Video 5: Reproductive Number [Video]. https://youtu.be/ju26rvzfFg4
Center for Infectious Disease Dynamics (CIDD). (2014b, March 19). Week 1 Video 6: Epidemic Curve [Video]. https://youtu.be/sSLfrSSmJZM
Cintrón-Arias, A. (2015, November 4). East Tennessee State University MATH 5880 Basic reproductive number [Video]. https://youtu.be/ItW-Q6Npapo
Delamater, P. L., Street, E. J., Leslie, T. F., Yang, Y. T., & Jacobsen, K. H. (2019). Complexity of the basic reproduction number (R0). Emerging infectious diseases, 25(1).
Read, J. M., Bridgen, J. R., Cummings, D. A., Ho, A., & Jewell, C. P. (2020). Novel coronavirus 2019-nCoV: early estimation of epidemiological parameters and epidemic predictions. medRxiv.
Woodward, A. (2020, January 31). The outbreaks of both the Wuhan coronavirus and SARS likely started in Chinese wet markets. Business Insider. https://www.businessinsider.com/wuhan-coronavirus-chinese-wet-market-photos-2020-1
Zhu, H., Guo, Q., Li, M., Wang, C., Fang, Z., Wang, P., … & Xiao, Y. (2020). Host and infectivity prediction of Wuhan 2019 novel coronavirus using deep learning algorithm. bioRxiv.
Anaphase 1. Chiasmata separate. Chromosomes (each with 2 chromatids) move to opposite poles. Each daughter is now haploid (n).
Telephase 1. Nuclear envelope may reform or it may just go into Meiosis 2.
Chiasmata. The point where paired chromosomes remain in contact together during meiosis 1. X-shape area. Help keep homologues together after synaptonemal complex breaks down.
Ends haploid.
Meiosis 2.
There is no copying of DNA when going from Meiosis I to Meiosis II.
“Meiosis for haploid cells”.
Starts haploid.
Meiosis 2 is shorter and simpler.
Cells entering are haploid. They have one chromosome from each homologous pair. Each chromosome still has 2 sister chromatids.
Prophase 2. Nuclear envelope (if it had reformed prior) breaks. Chromosome condense.
Prometaphase 2. Spindle is fully formed. Each sister chromatid forms an individual kinetochore that attaches to spindle.
Metaphase 2. Sister chromatids line up at metaphasic plate.
Anaphase 2. Sister chromatids split up and move to opposite poles. Pulled apart by kinetochore microtubules.
G0 Phase. The phase after mitosis and it can be a “dormant” type of phase before interphase actively begins again.
Interphase.
G1 (1st Gap) Phase. Physically grows larger and proliferates its organelles. Make a ton of shit to get ready to divide it up. Synthesize RNA and proteins. G1 Checkpoint. Make sure things are ready for DNA synthesis.
S (Synthesis) Phase. Duplicate DNA. Duplicate centrosomes.
G2 (2nd Gap) Phase. Grows more and makes more stuff to get ready for mitosis. G2 ends when mitosis begins. G2 Checkpoint.
Cell Cycle Regulation.
R, Restriction Point. Major checkpoint at end of G1 prior to S.
S phase checkpoint: CDK2 and Cyclin A.
G2 Checkpoint: CDK1 and Cyclin B.
M Checkpoint.
G1 Checkpoint: CDK4 and Cyclin D; CDK2 and Cyclin E.
Cdk. Cyclin dependent kinase. Adds phosphate to protein. Major checkpoint. If all is good, allows cell to move from G1 to S to G2 to M.
MPF. Maturation Promotion Factor. Includes Cdk and cyclins. Allows cells to move between phases.
p53. Protein that blocks cell cycle if DNA is damaged. If damage is real bad, causes cell apoptosis. p53 levels increased if DNA damaged; a “hold” is put and allows time for fixing DNA. p53 mutation is big factor leading to cancer.
p27. Binds to cyclin and Cdk, blocks entry into S phase.
Mitotic Phase (Mitosis).
Goal: divide the already duplicated DNA and divide the organelles to make two completely identical copies of the original cell.
Mitosis is nuclear division plus cytokinesis (division of cytoplasm, organelles, and cleaving/pinching off the cell membrane to make 2 distinct and identical cells).
Interphase. High metabolic activity. Chromatin are not distinct. A pair of centrioles have not yet been duplicated.
Prophase. Chromatin condense and are visible = chromosomes. Nucleolus disappears. Centrioles move to opposite poles. Mitotic spindle fibers begin forming.
Prometaphase. *Nuclear membrane dissolves. Proteins attach to centromeres (region where microtubules of spindle will attach), creating kinetochores (protein complex assoc. with centromeres).
Metaphase. Paired chromosomes line up at the metaphasic plate.
Anaphase. Paired chromosomes separate at kinetochores and move to opposite poles.
Telophase. Chromatids are at opposite poles, nuclear membrane reforms, chromosomes get all loose again = chromatin. Spindle fibers disassemble/disperse.
Cytokinesis. An actin ring forms and divides the cell.
Chromatin = DNA + structural proteins, histones. The loose, uncondensed form of DNA.
Chromosome = condensed form of DNA.
Chromatid = each of a sister chromatin. One of two identical halves of a replicated chromosome. The two identical copies are joined at the centromere.
Fatty acid (FA) synthesis has quite the different pathway from fatty acid catabolism/breakdown.
FA synthesis is made from glucose mainly in the liver (mostly liver) and adipocytes and mammary glands during lactation.
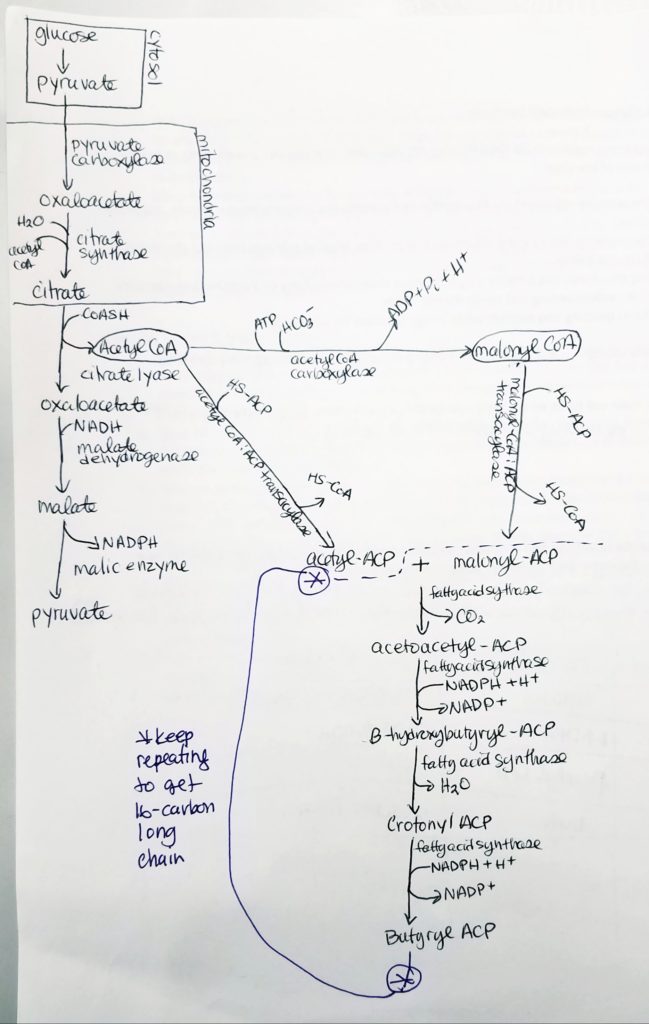
Glucose is converted to pyruvate in the cytosol. Pyruvate enter the mitochondrial matrix and is converted to acetyl CoA and oxaloacetate.
Acetyl CoA + oxaloacetate + H2O –> citrate (in mitochondria)
Citrate is moved out to the cytosol.
In the cytosol, citrate is cleaved into acetyl CoA and oxaloacetate.
The acetyl CoA (in cytosol now) transforms —acetyl CoA carboxylase–> malonyl CoA.
Malonyl CoA is the activated form of acetyl CoA.
Malonyl CoA (gets decarboxylated) is used to grow the FA chain.
When glucose is abundant and in excess, glucose may be converted and used this way for FA synthesis.
The fatty acid synthase complex is located in the cytosol (uses cytosolic acetyl CoA).
Citrate-Malate-Pyruvate shuttle provides cytosolic acetate units and reducing equivalens for the FA synthesis process.
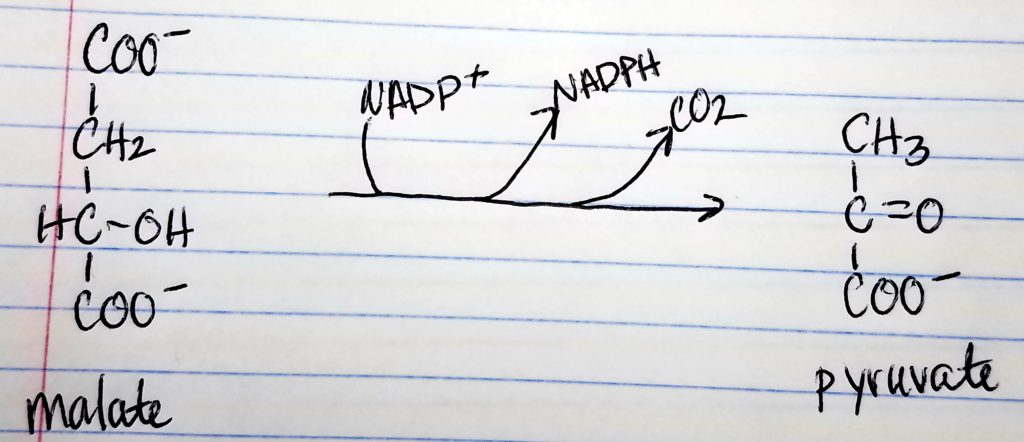
1 NADPH is made for each acetyl CoA that’s transferred from the mitochondria to the cytosol via malic enzyme.
Other NADPH molecules are produced from the pentose phosphate pathway as well.
Characteristics
Synthesis
Degradation
Location
Cytosol
Mitochondrial Matrix
Activated Intermediates
Bound to ACP
Thioester of CoA
Intermediates
-SH of acyl carrier proteins
-SH of CoA
Activated Enzymes
FAS (multienzyme complex)
4 distinct enzymes
Substrte
Acetyl CoA
Fatty Acids
Direction
Starts at methyl end
Starts at carboxyl end
Cofactors
NADPH/NADP+
FADH2/NADH, FAD/NAD+
Major Sites
Liver
Muscle & Liver
Hormonal Regulation
High Insulin/Glucagon Ratio
Low Insulin/Glucagon Ratio
Activator
Citrate
Free FA
Inhibitor
FA CoA
Malonyl CoA
How glucose can be used to make OAA and acetyl CoA.
Structures of malate conversion to pyruvate.
Acetyl CoA to Malonyl CoA.
Acetyl CoA gets converted to Malonyl CoA via enzyme Acetyl CoA Carboxylase + coenzyme Biotin.
This conversion is the most regulated step and it is the rate limiting step. It is reversible but this step is a commitment step to this pathway to make FAs.
Note that not ALL our acetyl CoA is going down this path. Assume there’s plenty other acetyl CoA to make Acetyl ACP as well.
1 ATP is spent.
One HCO3- (or CO2) is spent.
Some of our available acetyl CoA is used to make malonyl CoA.
Acyl Carrier Protein (ACP).
It is a complex with several binding sites for different activities.
It is a dimer.
The acyl carrier protein has a phosphopantetheine prosthetic group (can form thioester bonds) and a coenzyme A group.
Prosthetic group: A non protein that combines with a protein/enzyme.
The acetyl CoA and malonyl CoA get attached to ACP’s prosthetic group via the condensing enzyme acylmalonyl-ACP-condensing enzyme.
The phosphopantetheine group (B5) is the “docking” location.
The CoA part is where new materials are received.
Step 0: Activation/Loading.
Activation of acetyl CoA to acetyl-ACP (acyl carrier protein).Activation of malonyl CoA to malonyl-ACP (acyl carrier protein).
Fatty Acid Synthesis Step 1. Condensation.
Condensation
We are taking the “omega end” (the last end part) of acetyl ACP which is the H3C-C=O (keeping that from the acetyl ACP) and we get rid of the -O-C=O part of the malonyl ACP.
Loading.
Move the 2-carbon unit from malonyl-ACP to acetyl-ACP. Forms a 2-carbon keto-aceyl-ACP.
Omega carbon = last carbon in a chain.
Transfer 2 carbons from malonyl-ACP to acetyl-ACP thus forming 4 carbon keto-acyl-ACP
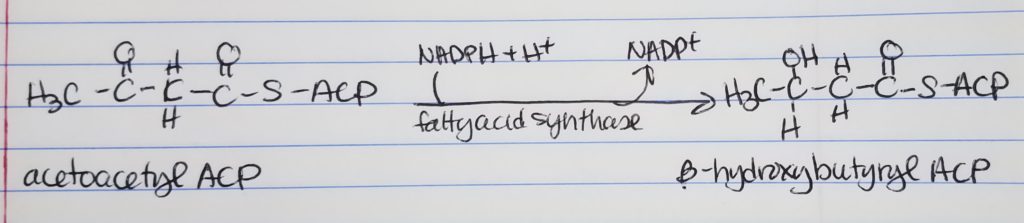
Fatty Acid Synthesis Step 2. Reduction.
Reduction
Get rid of the double bond, carbonyl, left of the CH2 group.
Convert keto-acyl-ACP to hydroxyl-ACP.
Spends 1 NADPH.
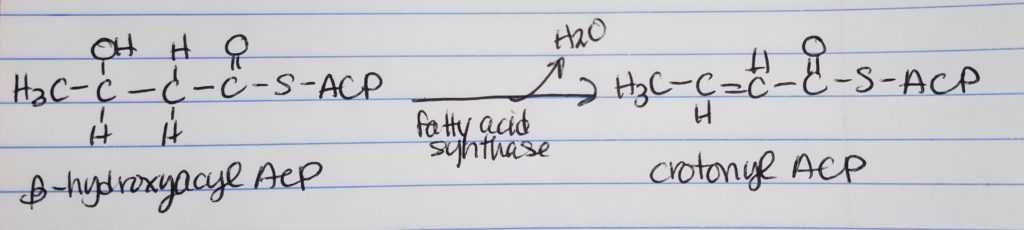
Fatty Acid Synthesis Step 3. Dehydration.
Dehydration
Want to get rid of the hydroxyl OH group by making a double bond.
Also, get rid of the OH group, water is leaving group.
Crotonyl-ACP is an enoyl-ACP.
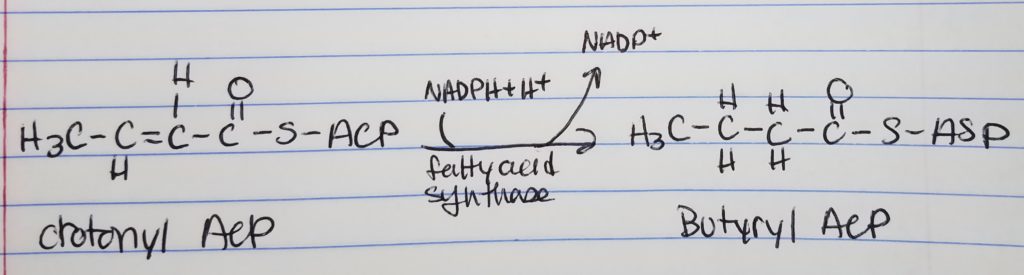
Fatty Acid Synthesis Step 4. Reduction.
Reduction
Want to reduce to get rid of that double bond (trans H), left of the carbonyl.
Spend 1 NADPH.
With butyrl ACP, that is a 4-carbon chain with 2-carbons from the acetyl ACP.
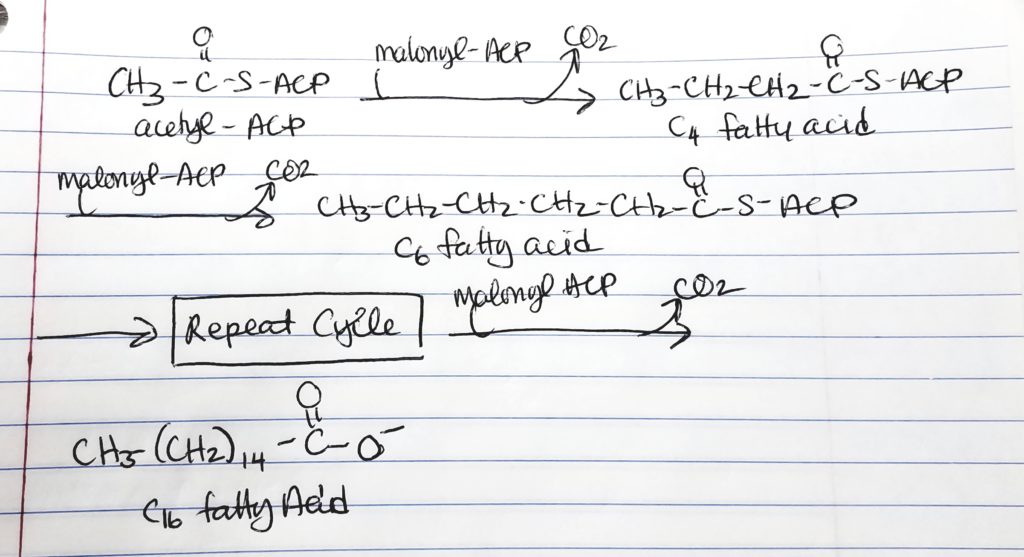
Hereafter, the cycle is repeated by adding malonyl ACP. This gives an addition of 2 more carbons to the chain.
1st time through the cycle, 2-carbons from acetyl ACP and 2-carbons from malonyl ACP = 4-carbon chain.
2nd time through the cycle, add 2 more carbons from malonyl to get a 6-carbon chain.
3rd time through the cycle, add 2 more carbons from malonyl to get a 8-carbon chain.
4th time through the cycle, add 2 more carbons from malonyl to get a 10-carbon chain.
5th time through the cycle, add 2 more carbons from malonyl to get a 12-carbon chain.
6th time through the cycle, add 2 more carbons from malonyl to get a 14-carbon chain.
7th time through the cycle, add 2 more carbons from malonyl to get a 16-carbon chain.
STOP at 16-carbon chain which is Palmitate because fatty acid synthase cannot handle anything more than the 16-carbon chain.
7 cycles are needed to make the 16-carbon palmitate.
7 cycles >> 1 molecule of acetyl CoA and 6 molecules of malonyl CoA; 14 NADPH; 7 ATP.
To make a complete palmitate:
How to Make a Long Fatty Acid? Keep repeating…
Keep adding malonyl ACP (adds 2 carbons each time) until a 16-carbon chain is reached.
Fatty acid synthase’s limit is 16 carbon chain.
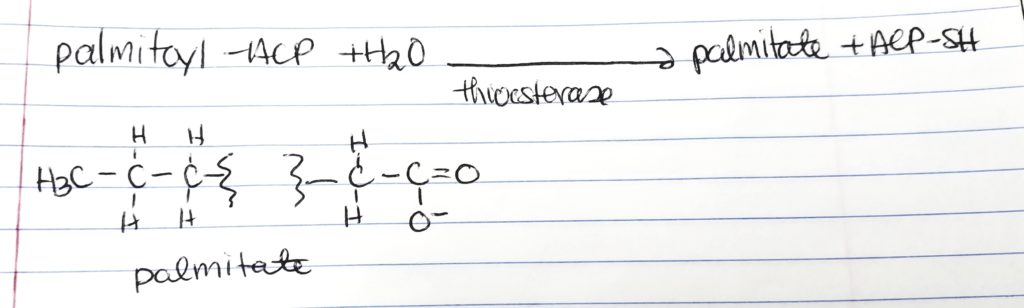
Palmitate.
At 16-carbon long FA chain, the enzyme thioesterase hydrolyzes the FA acyl group in order to make “free” palmitate.
Then palmitate can undergo elongation or unsaturation to make FAs.
Elongation and Unsaturation.
Elongase is an enzyme in the smooth endoplasmic reticulum (ER) that adds 2-carbons onto a FA chain via malonyl CoA.
Desaturase is an enzyme that adds cis double bonds up to position delta-9 in the ER in mammals. Humans can only use cis double bonds and not trans.
Summary of Key Points of FA Synthesis Steps.
Step 0. Activation-Loading. Acetyl CoA and malonyl CoA need to be “loaded” on to the Acyl Carrier Protein (ACP). Enzymes: acetyl-CoA:ACP transacylase; malonyl-CoA:ACP transacylase. The original CoA’s are replaced by ACP designation.
Step 1. Condensation. Acetyl-C0A:ACP and malonyl-CoA:ACP join to form a 4-carbon chain via fatty acid synthase. Enzyme: fatty acid synthase. A 2-carbon keto-acyl-ACP is formed. Released: CO3.
Step 2. Reduction. Convert the carbonyl carbon adjacent to the omega carbon from a double bonded to O to a single bond OH group. Converts keto-acyl-ACP to hydroxyacyl-ACP. Enzyme: fatty acid synthase. Spends: NADPH + H+ to NADP+.
Step 3. Dehydration. Need to remove the hydroxyl group at the carbon adjacent to the omega carbon. Forms a trans double bond between the second and third “to last” carbons in the chain. An enoyl is formed. Enzyme: fatty acid synthase. Released: H2O.
Step 4. Reduction. Get rid of the double trans bond from step 3 via reduction to form a fully saturated 4-carbon chain. Enzyme: fatty acid synthase. Spends: NADPH + H+ to NADP+.
Release Palmitate.
Fatty acid synthase can make up to a 16 carbon chain.
Palmitate is a 16 carbon chain.
When the cycle repeats and makes a 16-carbon long chain, thioesterase hydrolyzes it and frees up palmitate.
Palmitate itself can then elongate or desaturate (convert double bonds to single bonds).
Release palmitate.
Elongation an Desaturation.
After 16 carbons, elongase takes over. Elongase functions very much like FA synthase.
Regulation of Fatty Acid Synthesis.
Acetyl CoA carboxylase (ACC) is controlled by: glucagon, epinephrine, insulin.
ACC & glucagon. If glucagon levels are high, that means the body needs more blood sugar. It’s in a fasting state indicating that it is NOT the right time to be making fatty acids. Glucagon is an inhibitor.
ACC & epinephrine. Increased levels of epinephrine inhibit ACC. Increased levels of epinephrine indicate that the body needs more blood sugar (fight or flight). That is NOT the right time to make FAs.
ACC & insulin. Increased levels of insulin indicate that the blood has too much sugar floating around and insulin tells the cells to let blood sugar in (store or use). Insulin stimulates ACC which stimulates the production of FAs.
Other regulation types: citrate, palmitoyl CoA, AMP.
ACC is controlled via phosphorylation.
Insulin –> stimulates FA –> causes dephosphorylation of ACC.
Glucagon/epinephrine –> inhibits FA –> causes phosphorylation of ACC.
Protein kinase (AMP-PK): activated by AMP; inhibited by ATP.
ACC is inactivated when ATP is low.
Citrate allosterically activates ACC.
Citrate levels are high when acetyl CoA and ATP levels are high.
Isocitrate dehydrogenase is inhibited by ATP.
Carboxylase is allosterically inhibited by palmitoyl CoA.
Global regulation: +insulin, -glucagon, -epinephrine.
Local regulation: +citrate, -palmitoyl CoA, -AMP.
Formation of malonyl CoA inhibits carnitine acyltransferase I
Global Regulation.
If energy is low, then it is not the right time to make fatty acids.
ACC is inactivated when ATP levels are low.
Global regulations is achieved via reversible phosphorylation.
Aceytyl CoA is inhibited by phosphorylation and stimulated by dephosphorylation.
Insulin stimulates FA synthesis via dephoshorylation of ACC.
Glucagon and epinephrine inhibit ACC via phosphorylation.
Protein kinase is stimulated by AMP and inhibited by ATP.
Local Regulation.
Citrate allosterically activates acetyl CoA.
Citrate levels are high when acetyl CoA and ATP levels are in excess (isocitrate inhibited by ATP).
Palmitoyl CoA allosterically inhibits carboxylase.
Fed.
Increased insulin levels.
Inhibit hydrolysis of triacylglycerides.
Stimulates increase of malonyl CoA.
Increased malonyl CoA inhibits carnitine acyltransferase I.
FA stay in cytosol (FA oxidation enzymes are in mitochondria); so FA do not oxidize.
Fasting.
Epinephrine and glucagon at increased levels.
They stimulate adipose cell lipase.
Levels of free FA increase.
Inhibit ACC to decrease formation of malonyl CoA (causes more FA transported to mitochondria for beta-oxidation).
Cholesterol Metabolism.
Cholesterol.
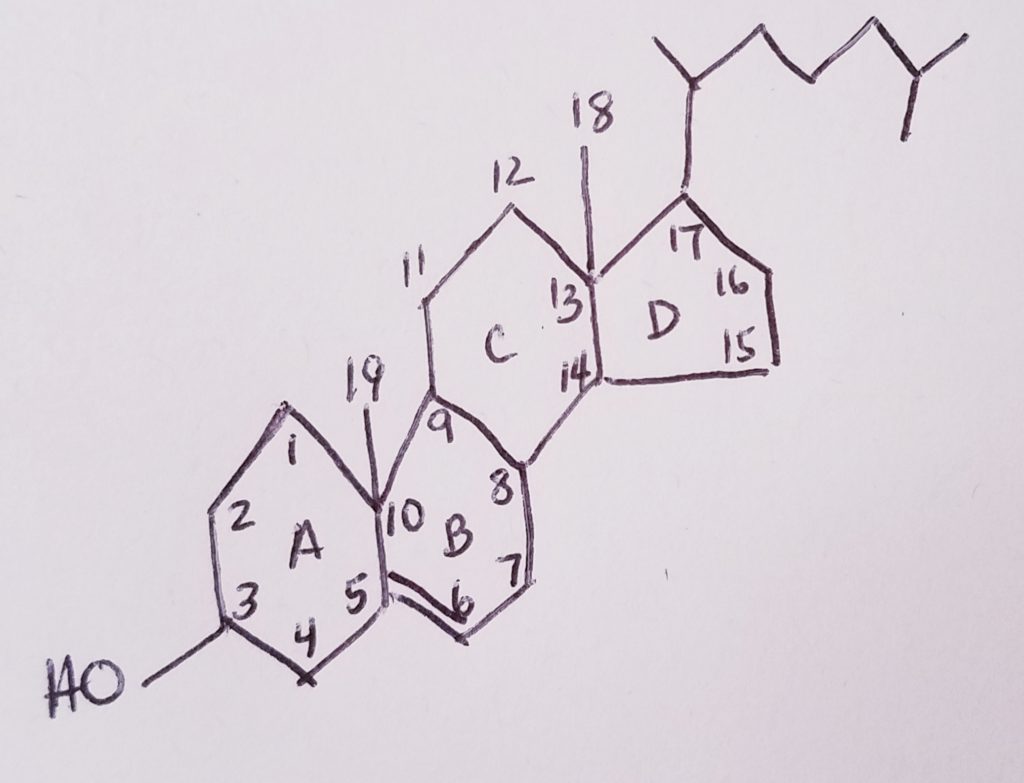
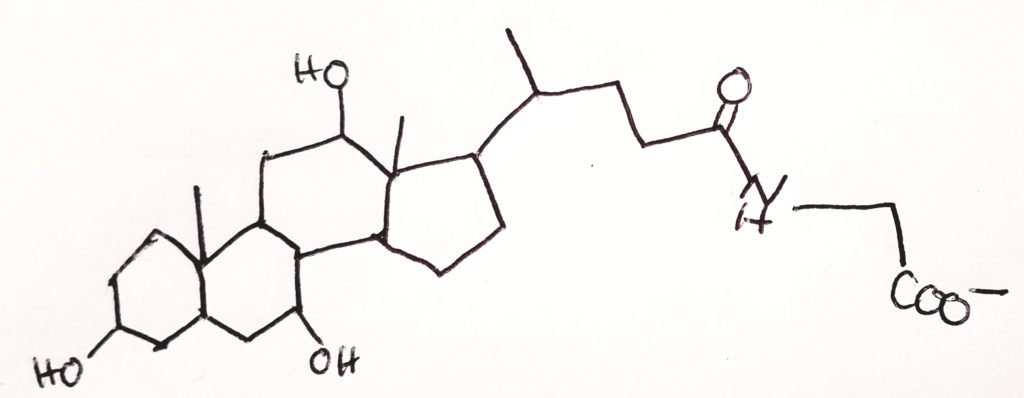
Cholesterol = steroid nucleus (sterane) that contains lipid and has a hydrocarbon tail.
Cholesterol is a lipid.
4-ring steroid nucleus. It’s very hydrophobic.
Ring A is a hexagon with OH at carbon-3 position.
Ring B is a hexagon with a CH3 (methyl) at position carbon-10. The methyl’s carbon is #19.
Ring C is a hexagon with a CH3 (methyl) at position carbon-12. The methyl’s carbon is #18.
The hydrocarbon tail would be at carbon-17.
A double bond from carbon-5 to carbon-6
27-carbon non-glyceride lipid.
Amphipathic: polar OH at C3; non-polar nucleus and tail at C17.
Made by most body cells: liver, intestines, cortex, brain, reproductive tissues.
Plasma cholesterol is often esterified (cholesterol ester at C3).
Phytosterol.
Plants don’t use cholesterol. Mammals only make cholesterol.
The plant-equivalent of cholesterol is phyosterol.
Flow of Major Cholesterol Intermediates: Number of Carbons and Number of Acetyl CoA.
Stage 1. Acetyl CoA to Mevalonate (2-carbons to 6-carbons).
3 x acetyl CoA (2-carbon) –> mevalonate (6-carbon).
If there’s high cellular cholesterol, the gene to make more HMG-CoA reductase enzyme is suppressed. This results in fewer and fewer copies of the HMG-CoA reductase enzyme and hence, the production of cholesterol slows down.
Statins, Muscle Pain, Ubiquinone (CoQ).
It is unknown why statins may cause muscle pain in some people.
CoQ supplementation may be helpful and CoQ is relatively “safe”.
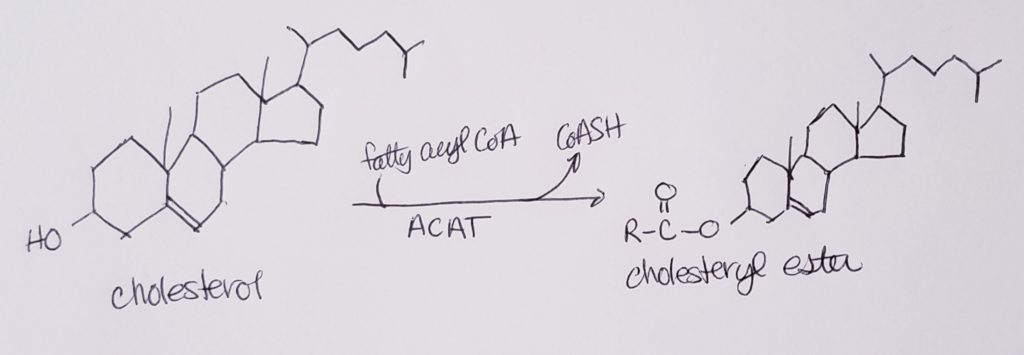
Cholesterol Esterification.
Cholesterol may “hitch a ride with” lipoproteins, but that limits cholesterol to the surface or lipid portion of those lipoproteins.
Esterifying cholesterols allow them to become more incorporated or at least, not limited to reside “on the surface”.
Esterification allows cholesterols more access to the interiors of lipoproteins or other structures that have both the hydrophobic and hydrophillic characteristics.
Esterification also allows for greater carrying capacity of lipoproteins.
Esterification converts cholesterol to an even more hydrophobic form.
This is done in the liver via enzyme acyl-CoA-cholesterol acyl transferase (ACAT).
Bile Acids and Bile Salts.
Bile is a mix of: water, electrolytes, organic materials, cholesterol, lipids, phospholipids, bilirubin and other waste products that get secreted into the bile and excreted.
Bile helps us breakdown food.
Bile helps us absorb fat soluble vitamins A, D, E, K.
Adults can make 400-800 ml of bile/day.
Liver cells (hepatocytes) make bile which run down the canaliculi ducts to the bile ducts. During this journey, bicarb is added into the mixture.
Bile ends up in the gall bladder which helps to concentrate the mixture (during the body’s fasting state). Bile can be 5x more concentrated.
To get rid of excess cholesterol, the bile is the way to go. The bile helps make cholesterol less hydrophobic via bile acids and lipids (e.g. lecithin). Cholesterol gets trapped in all the muck and can excrete it.
Bile acids/salts can emulsify fats and take on a micelle form.
Cholesterol can be converted into bile cholic (2nd most abundant) and chenodeoxycholic (most abundant) acids.
Cholic and chenodeoxycholic acids can be conjugated to glycine or taurine. This would make the “active forms”.
Primary bile acids made in liver via cholesterol made in the liver: cholic and chenodeoxycholic acids.
These primary bile acids travel into the small intestine where bacteria reacts with the primary acids. They undergo dehydroxylation (a heating reaction where OH is released as water). The result are the secondary bile acids.
Secondary bile acids: Deoxy Cholic Acid (Deoxy CA or DCA) and Litho Chenodeoxy Acid (Litho CA or LCA)
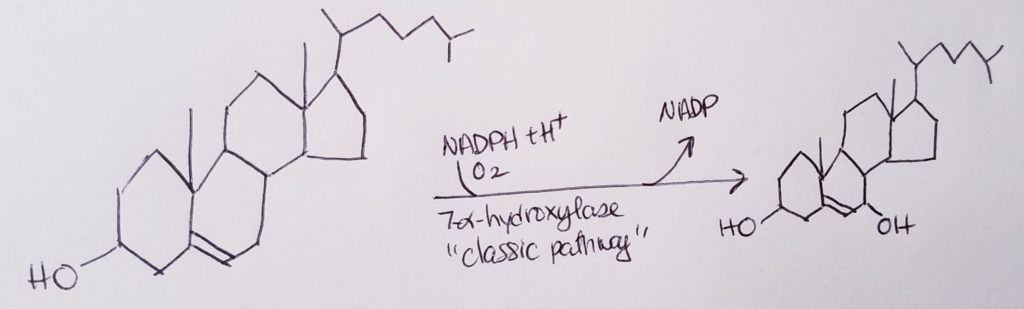
To make bile acids…the rate determining step is: Cholesterol –7alpha-hydrolase–>7alpha-hydroxycholesterol.
7alpha-hydroxycholesterol is the precursor to bile acids.
The glycine or taurine can be found attached onto the 24th carbon of the hydrocarbon tail.
Bile salts glycocholic acid and taurocholic acid.
Bile salts help digestion, eliminate waste products, help absorb fat-soluble vitamins and other components that the body needs.
Vitamin D, Calcitriol.
Vitamin D3 (cholecalciferol) is made in the skin in the presence of sunlight.
25-hydroxycholecalciferol is made from cholecalciferol
In the liver, Cholecalciferol –25-hydroxylase–> 25-hydroxycholecalciferol
In the kidney with enzyme 1-alpha-hydroxylase helps convert 25-hydroxycholecalciferol into the active form of vitamin D, 1,25-dihydroxycholecalciferol.
Sources of natural cholecalciferol (vit D3): fish and meat.
Sources of ergocalciferol (vit D2): plants and fungi.
5 Types of Steroid Hormones Derived from Cholesterol.
Mineralocortictoids. Made in adrenal cortex. Eg. Aldosterone C21 (conservation of Na+).
Glucocorticoids. Made in almost every mammalian cell. Eg. cortisone C21.
Androgens. Male testes. Eg. testosterone C19.
Estrogens. Ovaries. Eg. Estradiol
Progesterone. Ovaries, placenta, adrenal gland.
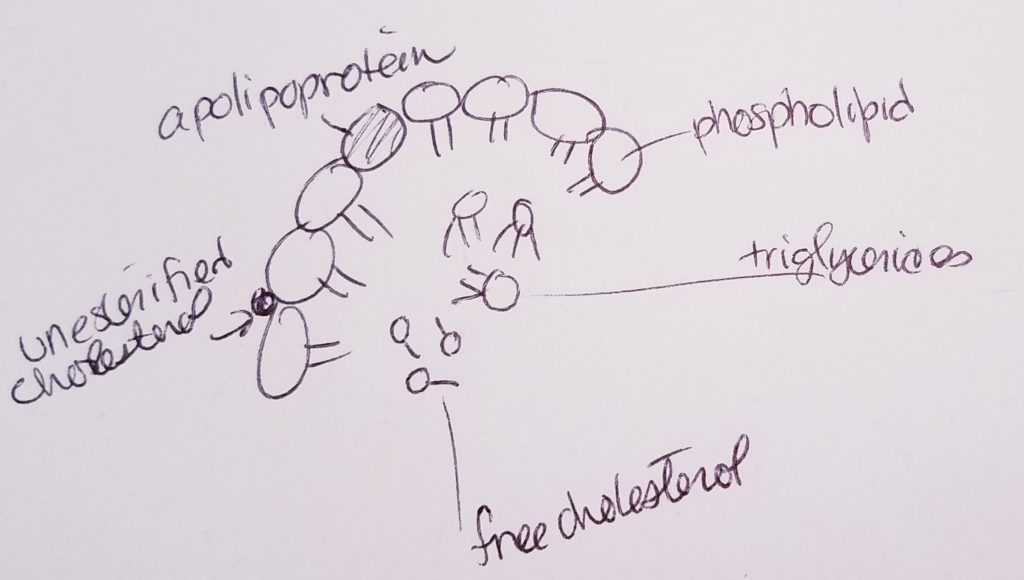
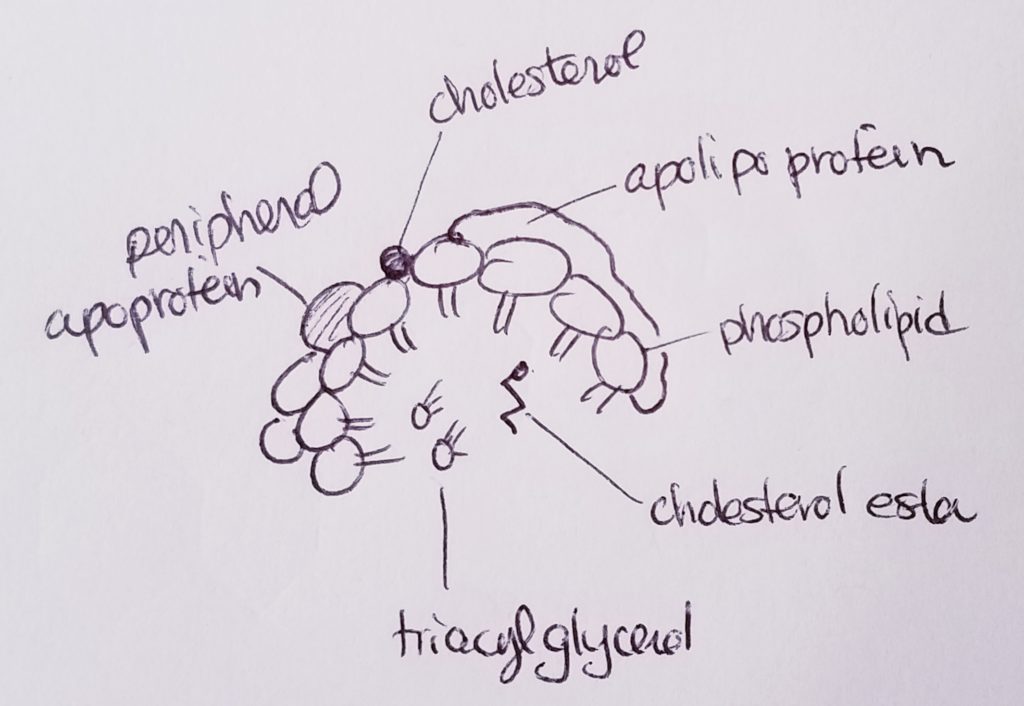
Lipoproteins (transport cholesterol).
Lipoproteins are proteins that can help transport lipids.
Types of lipids that may be transported via lipoprotein: fatty acids, triacylglycerols, phospholipids, free cholesterol, cholesterol ester, fat-soluble vitamins.
5 main types of lipoproteins: 1.Chylomicron. Transport dietary lipids from intestines to other places in the body. 2. VLDL, very low density lipoprotein. Carry cholesterol to tissues. 3. IDL, intermediate density lipoprotein. Functions like LDL, carrying cholesterol and fats. 4. LDL, low density lipoprotein. Can buildup in vessels. 5. HDL, high density lipoprotein. Carry cholesterol back to liver.
Density and size are inversely proportional (denser, smaller vs. less dense, fluffier and bigger).
Liver: makes VLDL and HDL.
Intestine: chylomicron, HDL.
Apolipoproteins (bind lipids to proteins to make lipoprotein).
Apo A1. HDL.
Apo B48. Chylomicron.
Apo B100. VLDL, IDL, LDL.
Apo C2. VLDL, chylomicron.
Apo E. IDL, chylomicron remnants.
Hormones.
Hormones are chemical messengers (from the endocrine system) that help regulate the body and maintain homeostasis.
Some hormones travel all over the body via bloodstream.
Some hormones are more localized.
Fed & Fasting States.
Hormones are chemical messengers. Released from the endocrine glands, they get secreted into blood.
Pancreas > Islet of Langerhans (beta cells) makes insulin.
Pancreas > Alpha cells make glucagon.
Pancreas > Delta cells make somatostatin.
Note somatostatin: It’s made in more than one place. In the pancreas, somatostatin can inhibit insulin and glucagon. Somatostatin that’s produced in the pancreas affects/regulates the pancreatic hormones.
Insulin.
Insulin dominates the FED state.
Stimulates: glucose oxidation; glycogen synthesis; fat synthesis; protein synthesis.
Insulin is a polypeptide derived from the prohormone proinsulin.
The C-peptide is cleaved from the insulin precursor.
Insulin has two chains connected via disulfide bridges.
Insulin stimulates tissues (esp. liver, muscle, adipose) to increase the uptake of glucose and amino acids. If the glucose/amino acids isn’t needed for immediate use, then package it into a storage form.
+Blood glucose. When blood glucose is abundant, insulin is activated to tell cells to use/store the blood glucose.
+Amino acids.
+Neural input.
+Gut hormones.
-Epinephrine (adrenergic).
Regulators of Glucagon.
-Glucose.
-Insulin.
-Amino acids.
+Cortisol.
+Neural (stress).
+Epinephrine.
Other Regulators.
Glucocorticoids (cortisol): stimulate gluconeogenesis and lipolysis and increase protein breakdown.
Epinephrine/norepinephrine: stimulate glycogenolysis and lipolysis (exercise).
Growth Hormone: stimulates glycogenolysis and lipolysis.
Thought Exercise: What Happens Right After a Meal vs. What Happens a Few Hours After a Meal??
Digestion.
Digestion is the process of converting and breaking down food into simpler components that the body can absorb (and deal with) and use.
The digestive/GI tract is where digestion-absorption takes place.
The route is: mouth, esophagus, stomach, small intestine, large intestine.
Denaturing: is unfolding of proteins or altering the structure in 3D space without breaking bonds.
Breaking down: is snipping or cutting protein via break bonds.
Digestive Path.
Salivary glands. Start salivating to help lubricate foodstuffs.
Mouth. Amylase helps start the breakdown of carbs. Mechanical and chemical breakdown starts.
Pharynx. Swallows foods/liquids.
Esophagus. Transports food.
Stomach. Churns foods. Pepsin helps break down protein. Stomach HCl helps breakdown food and kill germs. Mucosal lining helps protect the stomach and our tissues from the harsh acidity.
Liver. Makes bile. Filters nutrients. Stores vitamins and iron. Destroys wastes and toxic materials.
Gall Bladder. Stores and concentrates bile.
Pancreas. Makes hormones. Bile ducts pass through to empty bile in duodenum of the small intestine. Hormones insulin and glucagon. Add bicarb to the bile and help neutralize stomach acid. Trypsin and chymotrypsin help digest proteins. Amylase helps digest polysaccharides. Lipase digests lipids.
Small Intestine. Absorb most of our stuff.
Large Intestine. Absorb most of our water.
Rectum.
Anus.
Pancreatic amylase: helps break down dietary carbohydrates.
Brush border disaccharidases: enzymes that help break down disaccharides in the small intestinal wall.
Glycogen is stored in the cytosolic granules of the muscle and liver cells.
Glycogen is important to the body particularly for the CNS because the CNS is an obligate user of glucose.
IN THE LIVER, glycogen is broken down or stored in order to maintain the correct balance of blood sugar. There’s about 100g or about 10% glycogen in fresh weight well fed adult liver.
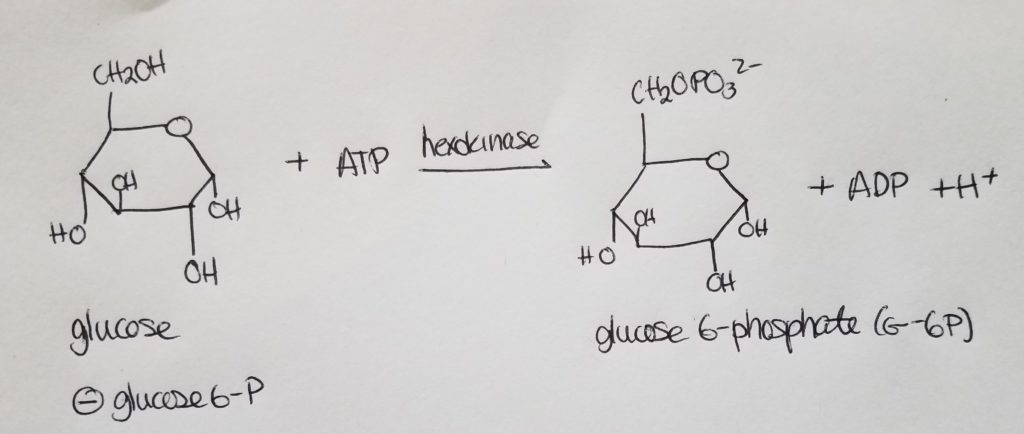
IN THE LIVER, the enzyme that transforms glucose into glucose 6-phosphate is called glucokinase.
IN THE MUSCLES, glycogen is used for energy especially for anaerobic high intensity bouts. There’s about 400g glycogen or 1-2% of fresh weight muscle.
IN THE MUSCLES, the enzyme that transforms glucose into glucose 6-phosphate is hexokinase.
Glycogen is a branched-chain polymer made up of glucose monomers linked up via alpha-1,4-glycosidic bonds in a straight chain, and alpha-1,6-glycosidic bonds at branches.
There are more alpha-1,4-glycosidic bonds than the alpha-1,6 bonds.
After about 8-14 glucose residues, a branch occurs.
Nonreducing ends. The 1,4-glycosidic bonds dominate the structure and their “ends” have a free hydroxl group at carbon 4. These are called the nonreducing ends.
Reducing end. The rightmost oriented glucose has a free anomeric carbon and is called the reducing end. This reducing end is usually attached to a protein (glycogenin).
Reducing sugars: sugars that can freely open and close their ring-form.
Is the anomeric carbon free? If something is bonded to the sugar at the anomeric carbon (carbon 1) this “blocks” the sugar from freely opening and closing its ring form. Thus the sugar is not reducible.
When studying glycogen, a protein is often bound to the glycogen at the carbon 1 position. This improves stability as the sugar cannot freely “shift” between open- and closed-ring forms.
Glycogenin: is an enzyme/protein that serves as the “head” or “anchor” where glycogen chains and branches can attach. Glycogenin is attached to the first glucose in a glycogen chain. Glycogenin initiates glycogen synthesis. Afterwards, glycogen synthase takes over.
Futile cycling: aka substrate cycling; substrate gets converted into product via one pathway and then the product gets converted back to the substrate in another pathway.
Glycogen
Muscle use of glycogen.
Liver use of glycogen.
Glycogenesis (Glycogen synthesis).
Glycogenesis occurs in the cytosol.
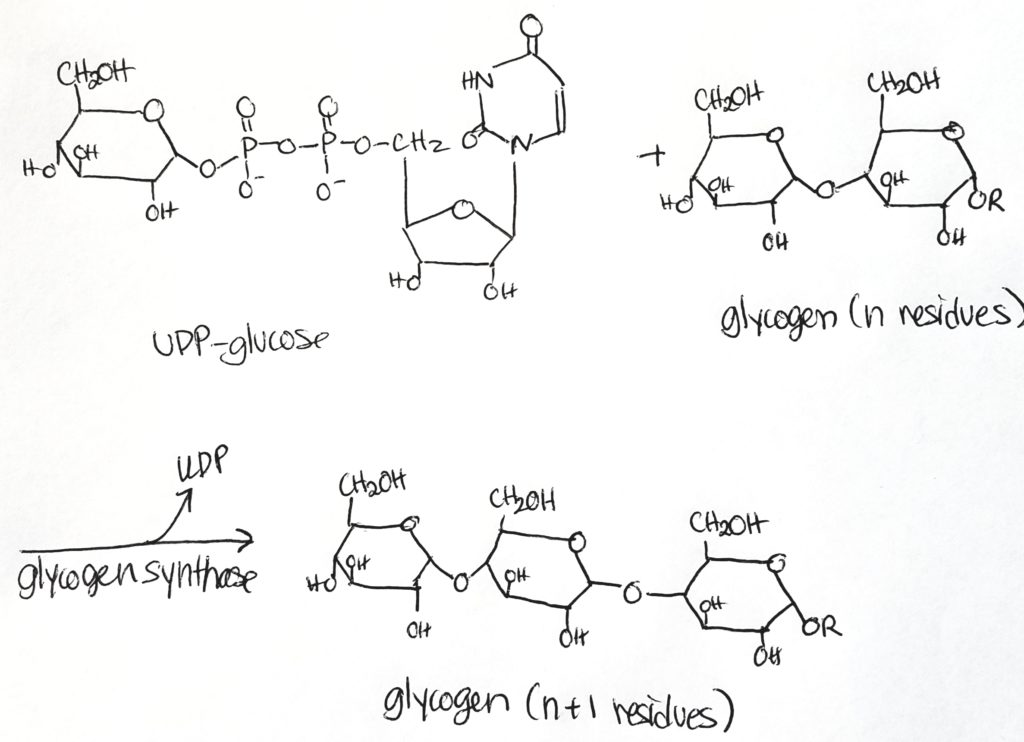
Glycogen is made from alpha-D-glucose.
ATP and UTP (uridine triphosphate) are used for energy in this process.
3 enzymatic steps convert G6P into glycogen.
Glycogen synthase is the major regulatory step. It makes alpha-1,4 bonds.
UTP/UDP are carriers.
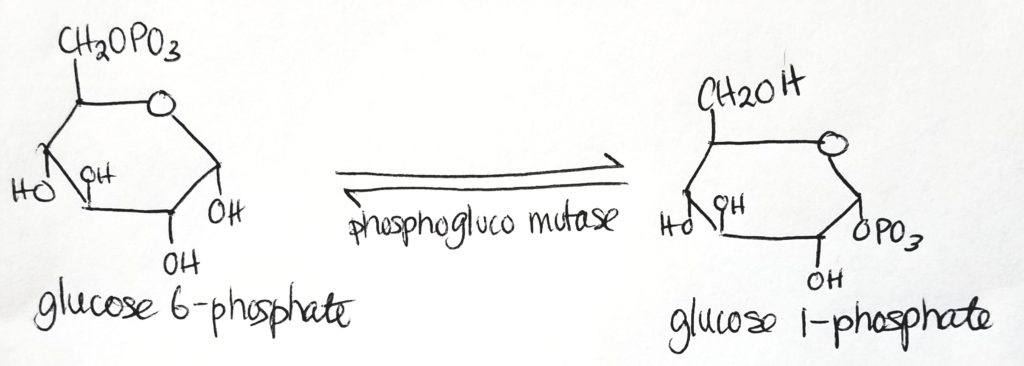
Mutase is a special form of isomerase. Mutases take a functional group at one position and moves it to another position.
Overall process for glycogen synthesis.
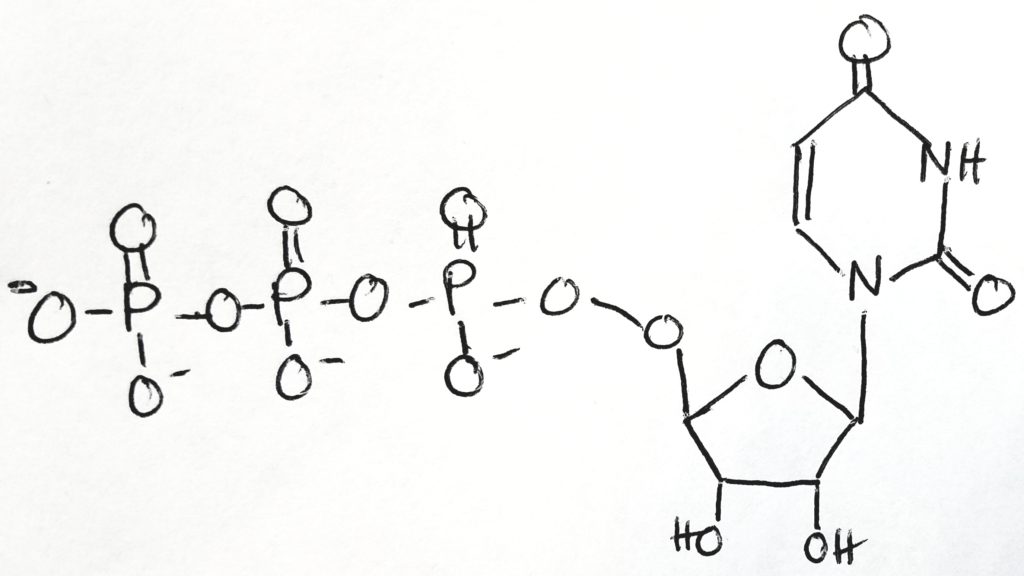
Uridine-5′-triphosphate ( C9H15N2O15P3 ).
UTP is a pyrimidine nucleoside triphosphate.
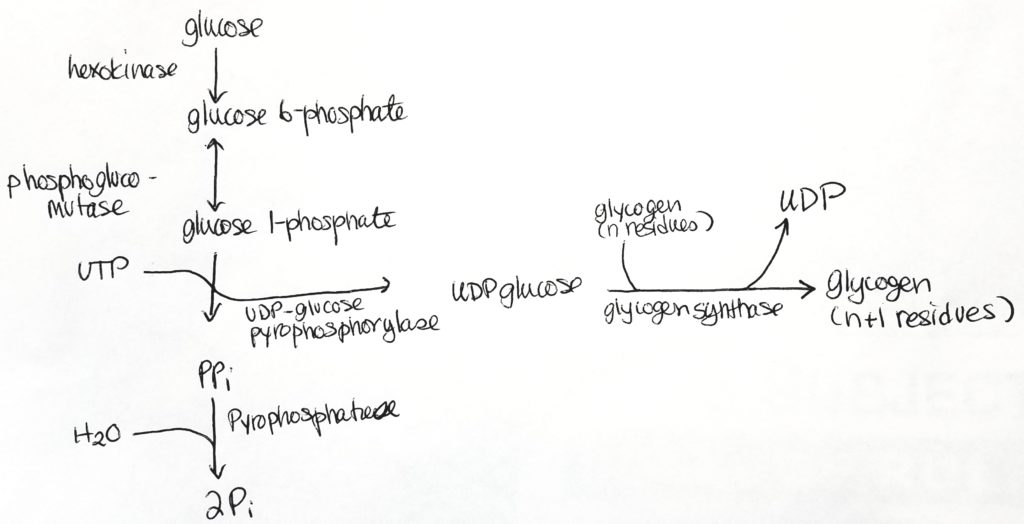
Step 1.
In the liver, glucose-6-phosphatase may cleave a glucose monomer of glucose 6-phosphate so that a glucose molecule may enter the bloodstream and be used by cells for energy.
glucose 6-phosphate + H2O –glucose-6-phosphatase–> glucose + Pi
Step 2.
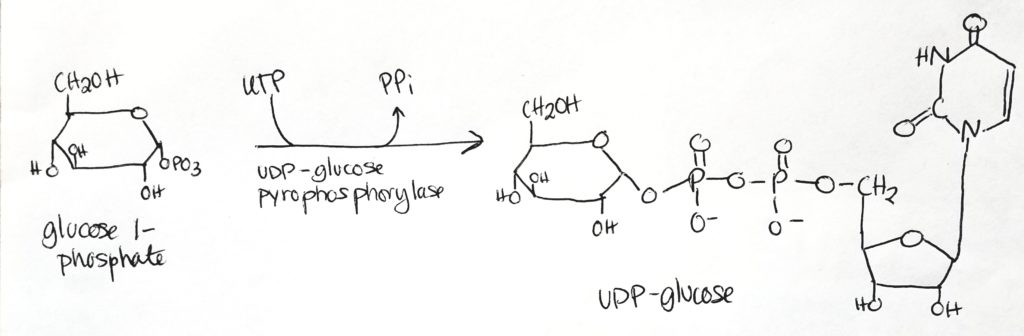
UDP-glucose is the activated form.
UDP-glucose is the form which is used directly to form glycogen.
Glucose 1-phosphate has one phosphate group.
Take UTP, free two phosphates from it as PPi.
Then attach UMP (monophosphate) to glucose 1-phosphate to get UDP-glucose (which now has 2 phosphate groups, one from previously and one from the UTP).
Cleavage of the phosphate bonds give enough energy to attach monomers to the glycogen chain.
Step 3.
https://youtu.be/P_5ubq6MikQ
Glycogen Synthesis Enzymes.
Glycogenin. Gets the process started and then glycogen synthase takes over. Glycogenin: is an enzyme/protein that serves as the “head” or “anchor” where glycogen chains and branches can attach. Glycogenin is attached to the first glucose in a glycogen chain. Glycogenin initiates glycogen synthesis. Afterwards, glycogen synthase takes over.
Glycogen synthase. Adds a glucose monomer to the chain (elongation process). Creates alpha-1,4-linkages only. Adds one glucose unit to an existing chain of at least 8 molecules (elongation).
1,4-Alpha-Glucan Branching enzyme. Takes 6-8 residues at a time and forms a new branching point. Creates alpha-1,6-linkages only. Branching is important in that it creates a lot more terminals and potential sites for phosphorylation and synthesis (make it easier to multitask by increasing more sites/terminals). Also increases solubility by making more “pockets” for water molecules to get into.
Putting a phosphate group onto something can alter it’s function and activate or deactivate it.
Rarely do we say “turn on” or “turn off”, because it’s not that black and white.
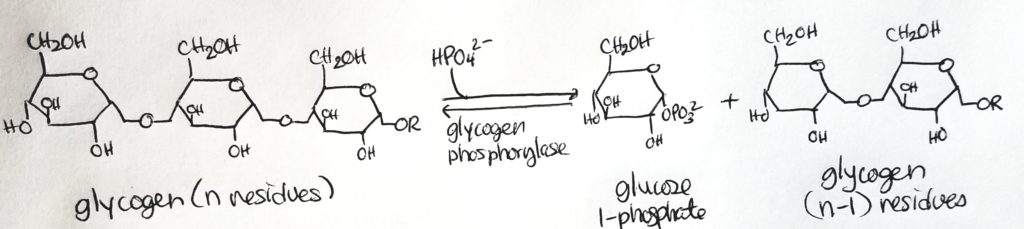
Glycogen phosphorylase. It is a dimer with quaternary structure. It has one copy “above” and one copy”below”. Specifically targets alpha-1,4-linkages. It cleaves off a glucose 1-phosphate. Once a glycogen chain gets down to 4 units of glucose monomer, glycogen phosphorylase cannot work. That’s where the debranching enzyme comes in.
Glycogenolysis.
Catabolic/breakdown of glycogen to glucose units so that the glucose can enter the bloodstream and be utilized or so that glucose can be utilized in the muscle.
This process uses Pi to cleave a glucose from glycogen (it’s not a hydrolysis reaction). It takes energy to cleave that glucose out.
This cleavage using Pi is called phosphorylation.
Glycogen phosphorylase is the enzyme that catalyzes this phosphorylation.
Glycogen Debranching Enzyme.
Another way to catabolize glycogen.
Glycogen phosphorylase (previously studied) was able to cleave a terminal glucose unit off of glycogen. Note that this unit is in the form glucose 1-phosphate.
Glycogen phosphorylase CANNOT act on any branches that are less than 5 glucose monomers long.
Glycogen debranching enzyme is a hydrolase (use water to cleave) NOT phosphorylase (using phosphate to cleave).
Glucose is the result of cleavage and NOT glucose 1-phosphate.
This enzyme has both a 4:4 transferase activity and a glucosidase activity.
Once a branch has been pruned such that there are only 4 glucose units on it, the debranching enzyme (the 4:4 transferase role) will prune the 3 terminal units of glucose from that branch and attach them to a longer branch/chain.
Then the debranching enzyme (glucosidase role) will prune off that lone glucose unit, making it available in the cell/bloodstream. Note that it is glucose and NOT glucose 1-phosphate or glucose 6-phosphate. It’s a straightup glucose.
Note that the glucosidase role of the debranching enzyme can only act to prune off a glucose unit that is 1 unit long. For example, if there is a branch of 2 glucose units, the debranching enzyme cannot act on it.
Note that the glucosidase role is a hydrolase. It uses water to cleave the glucose unit and set it free.
Regulation of Glycogen Metabolism.
Glycogen synthase and glycogen phosphorylase help regulate glycogen metabolism.
Both are allosteric regulators and respond to hormonal control (via phosphorylation and dephosphorylation).
Glycogen synthase is activated by glucose 6-phosphate (indicating glucose levels are high).
Glycogen phosphorylase is inhibited by high levels of glucose 6-phosphate and activated with high levels of AMP (indicating we need more energy).
Insulin.
Insulin is a hormone that responds to high blood glucose levels.
When blood glucose levels are high, insulin inhibits glycogen phosphorylase (don’t free up any more glucose because we don’t need it).
Insulin activates glycogen synthase.
Insulin is associated with the fed state.
Glucagon and Epinephrine.
These are active when there is low blood glucose.
These hormones inhibit glycogen synthase (we don’t want to store energy, we need energy to use now).
These hormones activate glycogen phosphorylase.
Associated with fasting state and/or exercise states.
Fatty Acid Metabolism (Oxidation).
What are fatty acids (FAs)? They are a carboxylic acid head with a long alipathic (non-aromatic) hydrocarbon tail.
What are fatty acids good for? Storage of energy; building blocks for other structures like phospholipid and glycolipids; used in eicosanoids structure and secondary messengers.
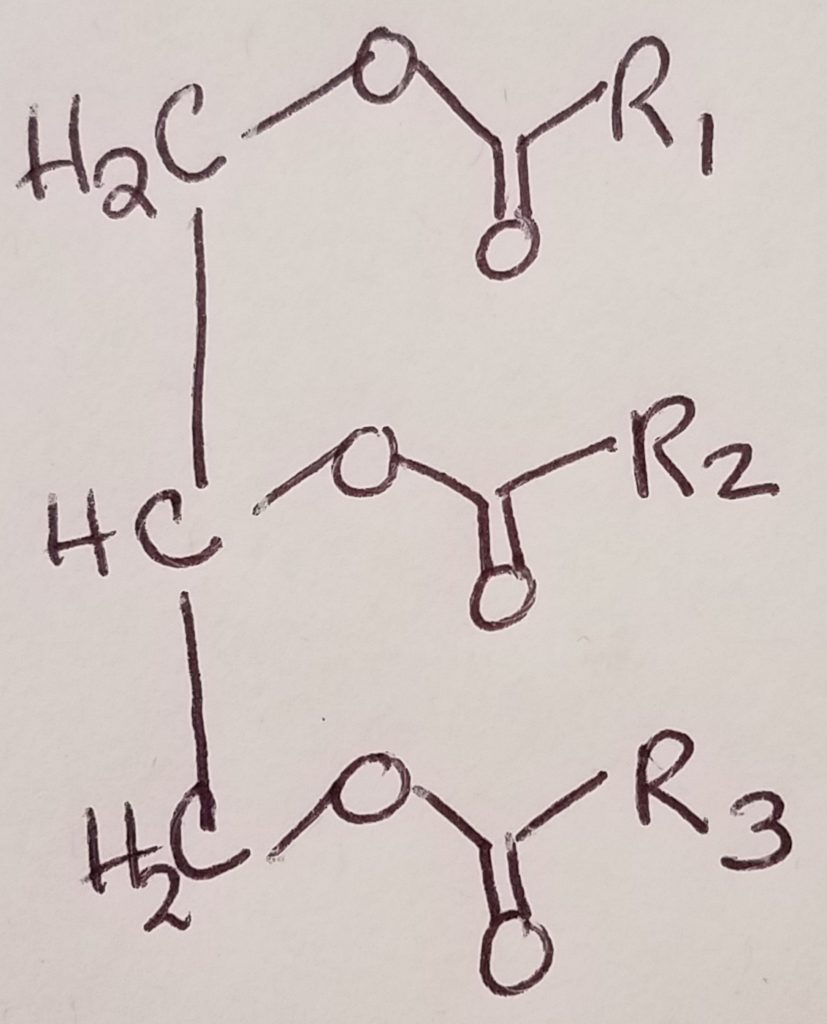
Triacylglycerol = triglyceride = glycerol + 3 FA chains.
Triacylglycerol is the simplest form of lipid.
FAs are very reduced and have lots of potential for oxidation (great source of potential energy).
FA oxidation produces NADH and FADH2 which can then be used in ETC to make lots of ATP.
Fats are efficient energy storage.
Carbohydrates = 4 kcal/g
Fats = 9 kcal/g
Advantages of fats over polysaccharides: FA has more energy per carbon because FAs are more reduced; FAs carry less water because they are nonpolar.
Short-term energy, “quick” delivery: glucose and glycogen.
Long-term energy, slower delivery: fats.
1/3 of our energy needs are from triacylglycerols.
The CNS and red blood cells cannot use FA’s because they don’t have the machinery to process and utilize FAs.
Fatty Acid Breakdown.
Bile salts. Made in the liver, trickle through bile ducts, and stored in the gallbladder until they are released into the duodenum. The gall bladder helps to concentrate the bile. Act as emulsifiers and keep fat from making large clumps of itself. As emulsifiers, help to increase the surface area of fat “droplets” so that enzymes can have an easier time to reach and act on the lipids. Without bile salts, enzymes may not be as efficient acting on large clumps of fats. Emulsifiers also help “fat droplets” move through the body better. Large fat clumps could potentially cause fatal blockages. Bile salts help to “solubilize” lipids/triacylglycerol.
Glycocholate or glycocholic acid is a crystalline bile salt used to help emulsify lipids.
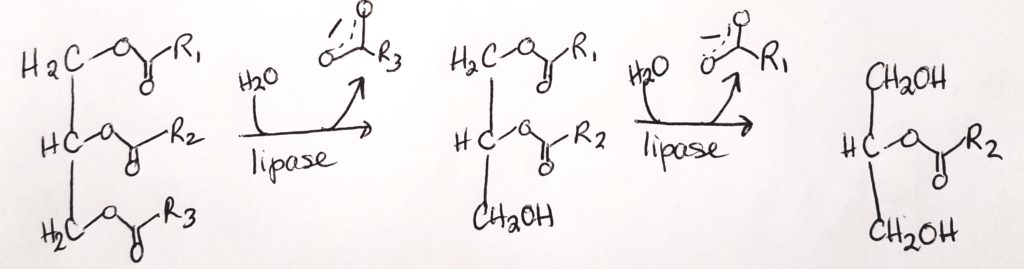
Lipases. Lipases are made in the pancreas and they help to hydrolyze ester bonds (RCOOR) of triacylglycerols.
FAs and two monoacylglycerols can then cross the plasma membrane of epithelial cells.
Triacylglycerol.
Lipase cleave triacylglycerol to diacylglycerol to monoacylglycerol.
Triglyceride Digestion & Absorption.
What kinds of lipids are in our diet? Triglycerides (triacylglycerols), fat-soluble vitamins, sterols (e.g. cholesterol), and “neutral fats”.
What needs to happen in order for lipids to serve our needs? Because lipids are hydrophobic and generally insoluble in water, lipids physically need to be broken down into teeny tiny particles held in a suspension so that they can travel in the body which is largely an aqueous environment. Then enzymes need to act on the lipid particles in order to convert them to a form that the body can use/absorb.
Digestion starts at the mouth.
Mouth: lingual lipase initiates the breakdown of lipids/fats.
Gall bladder – Liver: bile salts (amphipathic meaning they have both hydrophilic and hydrophobic qualities) are made in the liver and secreted/concentrated in the gall bladder. These bile salts are then released in the duodenum.
Pancreas: secretes HCO3-, lipase colipase (a protein coenzyme that aids the pancreatic lipase). Pancreatic lipase is largely responsible for the bulk of breaking down lipids into tiny particles. Pancreatic lipase is also water soluble.
Down in the stomach, the gastric lipase helps to break triacylglycerols into diacylglycerols…then break those down into fatty acid chains. The stomach churning and movement down into and through the intestines help keep the lipids emulsified (along with the bile salts, pancreatic lipase and colipase).
The bile salts help to surround the fats to form micelles–fatty acid core with a more water-soluble “shell” or exterior. Bile salts are like detergents.
Intestinal cells (enterocytes), are able to absorb the FAs and monoacylglycerols via FA protein transporter (to cross the cell membrane). The monoacylglycerols and fatty acids reassemble to form triacylglycerols. They are then attached to a protein carrier (lipoprotein).
Inside the cell, the FAs and monoacylglycerols goto the endoplasmic reticulum so that they can be used to build triglycerides (triacylglycerols).
From the ER to the Golgi Complex (of the intestinal cell, enterocyte) in assembly-line fashion, the triglycerides are packaged with cholesterol and lipoproteins into what’s called a chylomicrons.
This combination of lipoproteins (1-2%), cholesterol (1-3%), phospholipid (6-12%), and core of triacylglycerols (85-92%) result in what is called a chylomicron (like a “super-sized” micelle). Chylomicrons exit the enterocyte via exocytosis and can pass into the lymphatic system and out into the bloodstream. Once in the bloodstream, the chylomicrons can disassemble to be used.
Hormones can signal for lipolysis in adipose tissues: epinephrine, glucagon, cortisol promote lipolysis.
Insulin inhibits lipolysis.
FAs are bound to serum albumin for transport around the body.
The lipases break down chylomicrons into glycerol and FAs.
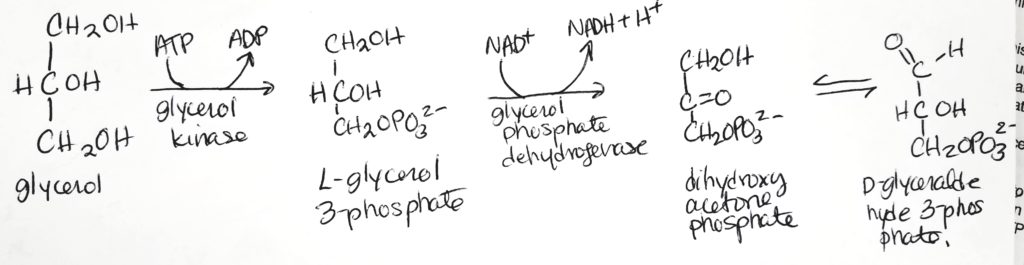
Glycerol can get recycled to D-glyceraldehyde 3-phosphate which is an important intermediate for both glycolysis and gluconeogenesis.
Conversion of glycerol (absorbed by liver) to glucose.
Fatty Acid Activation.
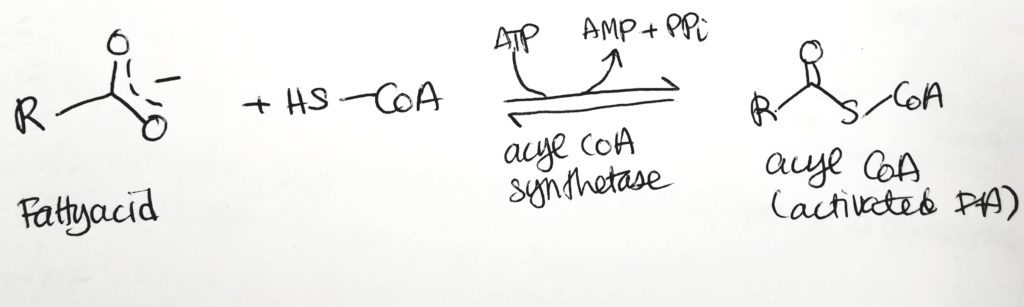
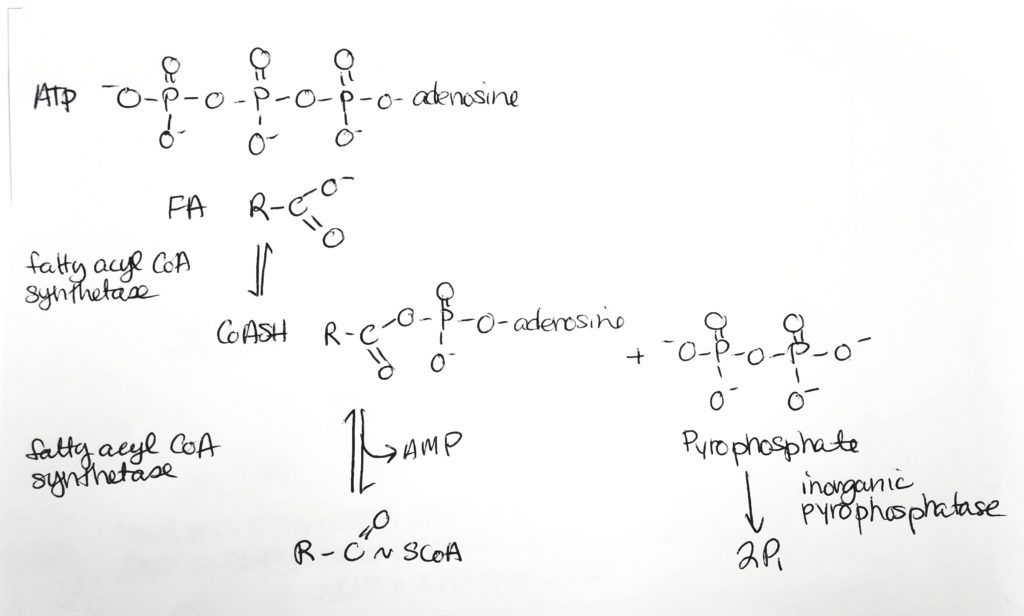
To oxidize FAs, first attach them to CoA and spend 2 ATP.
FA activation.Activation of FA. Costs 2 ATP to make the fatty acyl CoA.
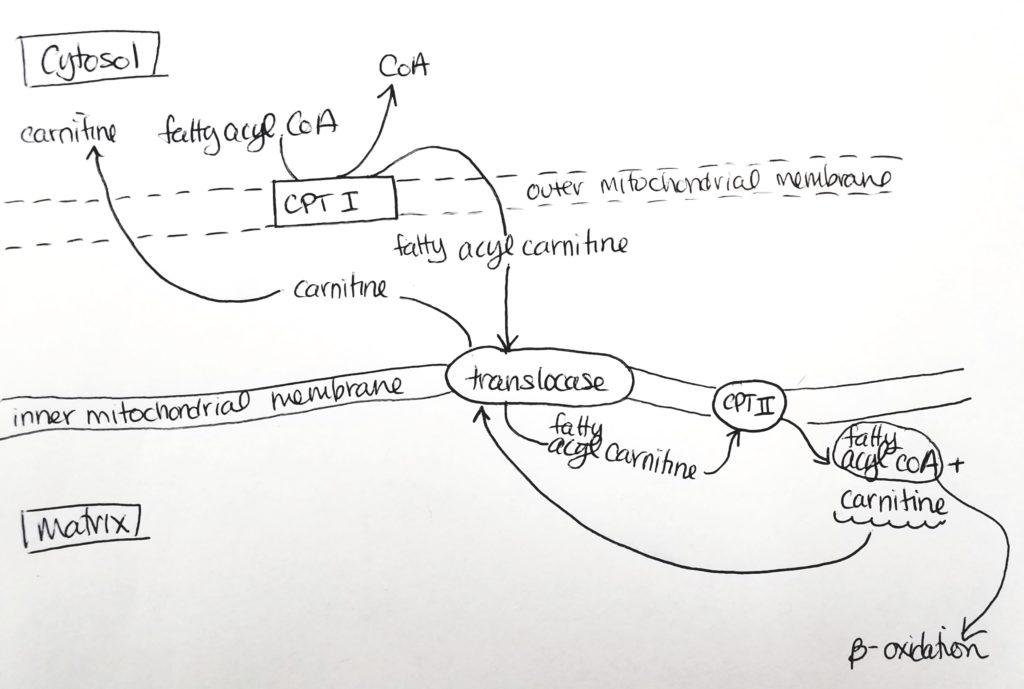
Getting the Fatty Acid into the Matrix.
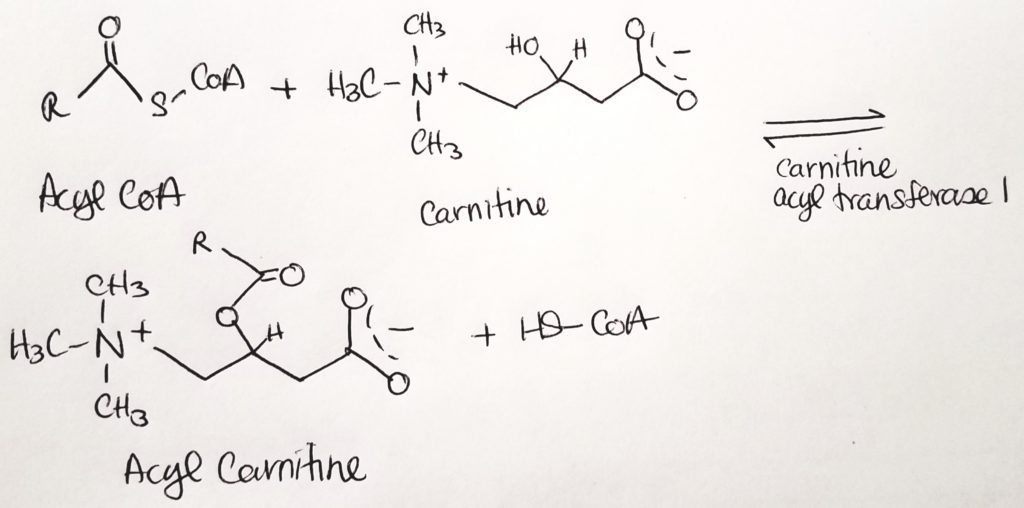
The fatty acyl CoA is shuttled via carnitine from the cytosol through the outer mitochondrial membrane (leaky) to the inner mitochondrial membrane.
Carnitine palmitoyltransferase I (CPTI) enzyme is located on the outer mitochondrial membrane. It packages the fatty acyl CoA with carnitine.
The fatty acyl CoA-carnitine is transported via carnitine translocase (enzyme) into the matrix.
Carnitine palmitoyltransferase II (CPTII) located on the inner mitochondrial membrane then strips off the carnitine. The carnitine goes back out to the cytosol to be recycled. Then the fatty acyl CoA now present in the matrix can undergo beta-oxidation.
Carnitine shuttles fatty acyl CoA to mitochondrial matrix for B-oxidation.Making fatty acyl carnitine.
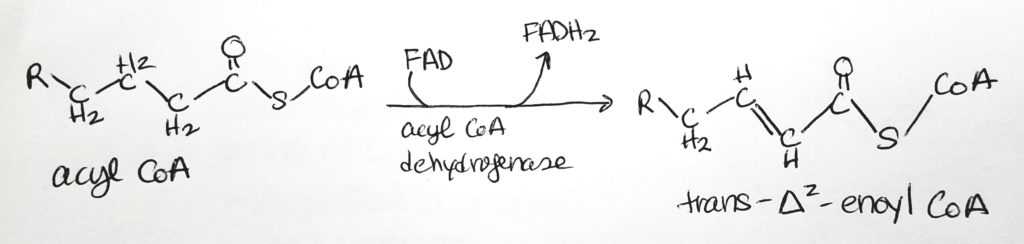
Beta-Oxidation.
Beta-oxidation is so named because the activity is at the beta-carbon site.
This is the catabolic pathway of fatty acids.
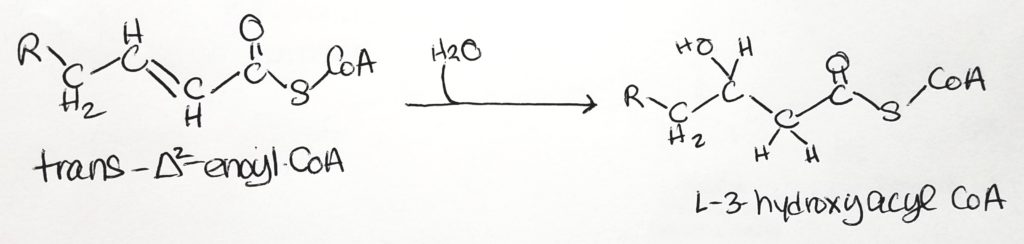
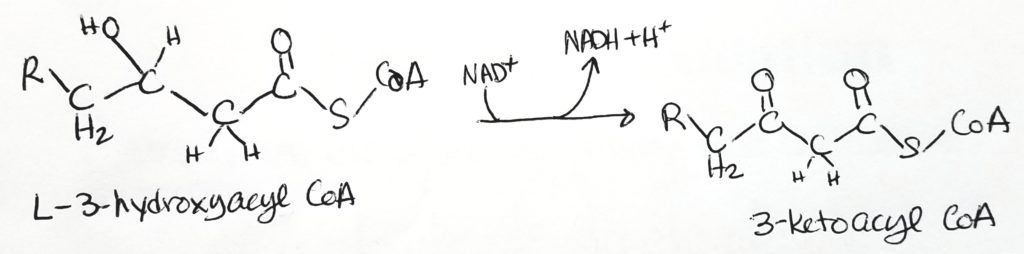
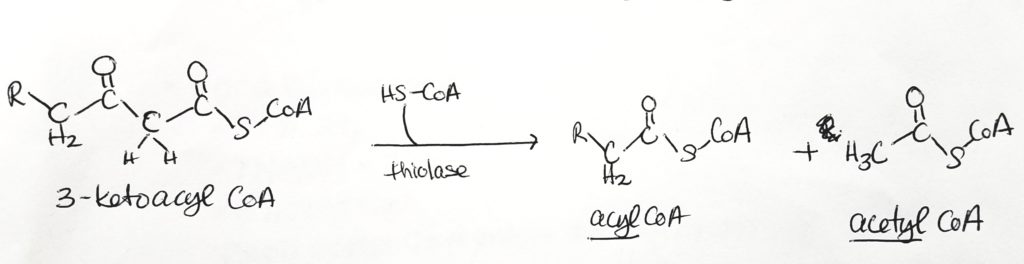
Step 1. The site of activity is the beta-carbon. FAD is the oxidizing agent. Converted to alkene. FADH2 is produced. Reaction type = oxidation.Step 2. Water added and alkene becomes alkane again. Hydroxyl group added to beta-carbon and hydrogen at alpha-carbon. Reaction type = hydration.Step 3. NAD+ is oxidizing agent. Alcohol converted to ketone. NADH produced. Reaction type = oxidation.Step 4. Acyl CoA and Acetyl CoA are formed via thiolase and thiolysis. Reaction type = oxidation and thiolysis.
Step 1. Oxidation. Makes 1 FADH2.
Step 2. Hydration.
Step 3. Oxidation. Makes NADH + H+
Step 4. Thiolysis tomake one acyl CoA and one acetyl CoA
Calculating Energy Exchange of Fatty Acid Oxidation. What do you really get?
Given n number of carbons.
You have n/2 pairs of carbons.
You cut the n long chain with (n/2)-1 many “snips”.
You have (n/2)-1 many FADH2.
You have (n/2)-1 many NADH and (n/2)-1 many H+
You have n/2 many acetyl CoA.
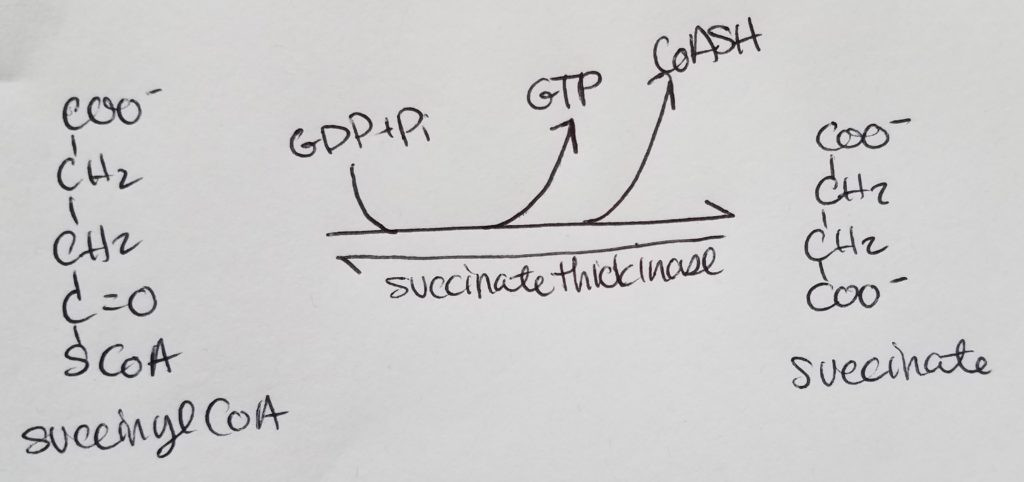
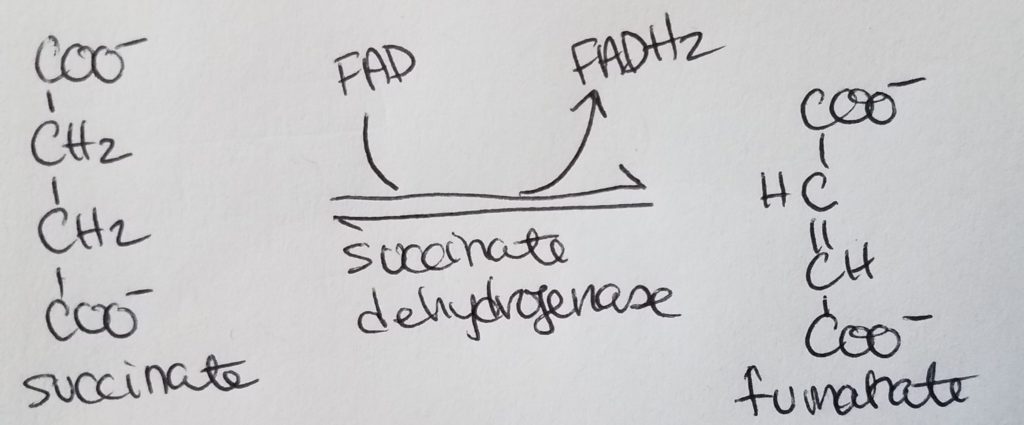
Each acetyl CoA will go through the TCA cycle to produce: 3 NADH, 1 FADH2, 1 GTP.
You will go through n/2 rounds of the TCA cycle to produce: n/2 * 3 NADH; n/2 * 1 FADH2; n/2 * 1 GTP.
FADH2 makes 1.5 ATP
NADH makes 2.5 ATP
1 GTP makes 1 ATP
As a shortcut you can think of each acetyl CoA that goes through the TCA makes 10 ATP.
What do you do with an odd-numbered FA chain?
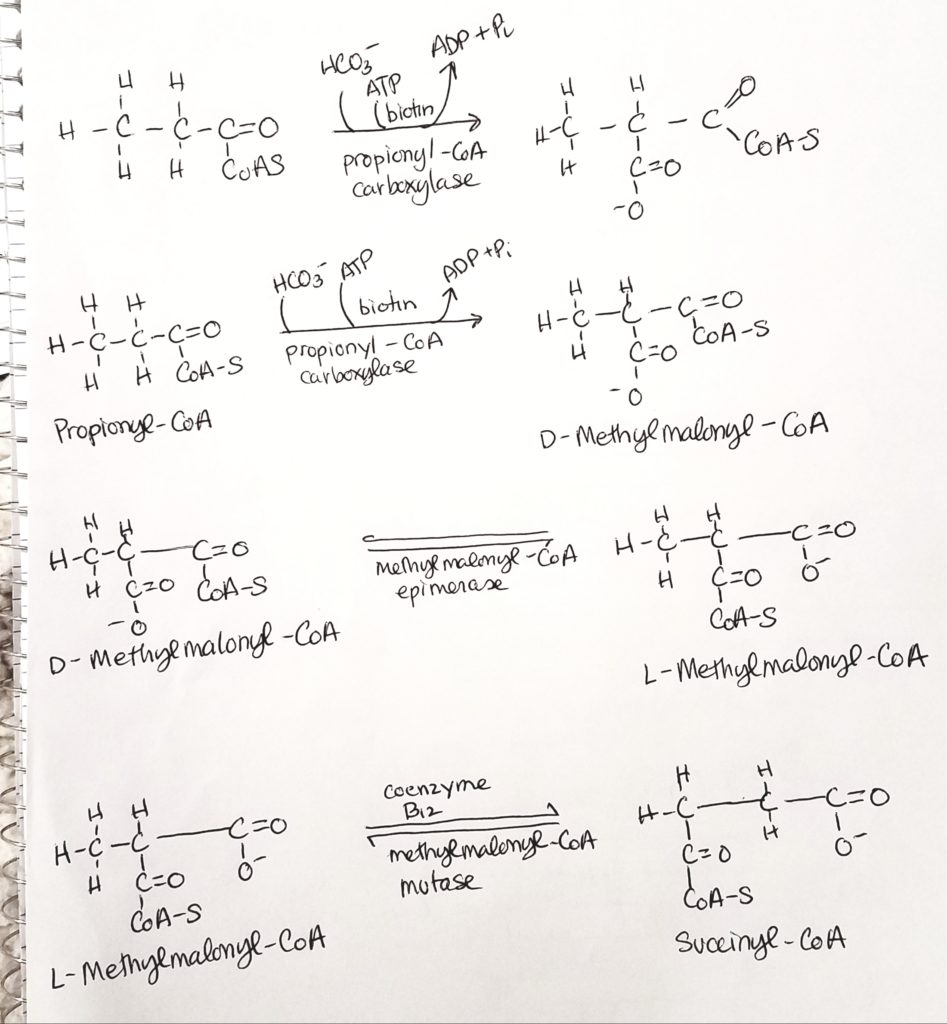
Don’t panic. Odd numbered FA’s make propionyl-CoA. The last fragment of 3 carbons is called propionyl-CoA. HCO3- (bicarb) and ATP are added (coenzyme biotin). Coenzyme B12 is also active to make 4-carbon succinyl-CoA.
The odd-numbered FA, the last fragment of 3 carbons is propionyl-CoA.
Let’s work an odd-numbered problem.
Say you have a 17 carbon FA.
(17/2) – 1.5 = 7 acetyl CoA.
You can do the math for the 7 acetyl CoAs.
REMEMBER to subtract the “cost” of 2 ATPs.
But what’s left over?
Propionyl undergoes carboxylations with biotin and B12 to produce succinyl-CoA.
Animals can’t use FAs to make glucose. Acetyl CoA can’t be converted to oxaloacetate.
Plants have enzymes that let them convert acetyl CoA to oxaloacetate.
Ketone Body Metabolism.
When lipid and carbohydrate metabolism are fairly balanced, most of the acetyl CoA from the FA beta-oxidation goes through the TCA cycle.
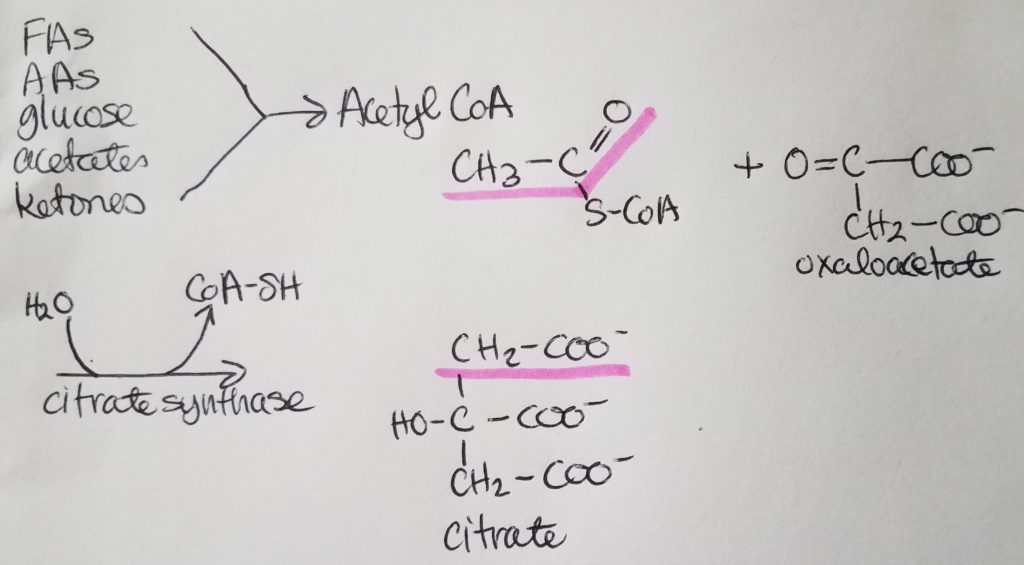
Remember that the first step in the TCA cycle is oxaloacetate + water + acetyl CoA –citrate synthase–> citrate.
BUT what if oxaloacetate supply is low? What do we do with the extra acetyl CoA?
Oxaloacetate supply may be low if carbohydrates are scarce (starvation) or improperly used (misappropriated) such as diabetes.
Oxaloacetate can be made from pyruvate via pyruvate carboxylase.
Acetyl CoA drives ketone body production. When acetyl CoA levels persistantly rise, this triggers ketogenesis.
What are ketone bodies?
Ketone bodies are 3 molecules produced in the mitochondrial matrix of hepatocytes (liver cells).
These 3 molecules are: acetone, acetoacetate, and beta-hydroxybutyrate.
The “making of” these 3 molecules is called ketogenesis. This occurs naturally in small amounts.
Ketone bodies.
When the body system is out of whack and acetone, acetoacetate, and/or D-beta-hydroxybutyrate are accumulated in eXcess, we call this state ketosis.
When lots more ketone bodies accumulate in eXcess and the body’s pH is drastically lowered to acidic levels, we call this ketoacidosis.
Synthesis of Ketone Bodies.
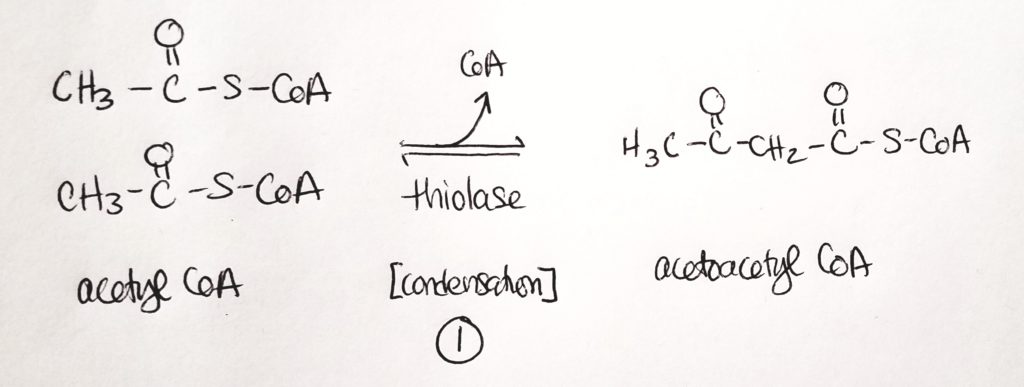
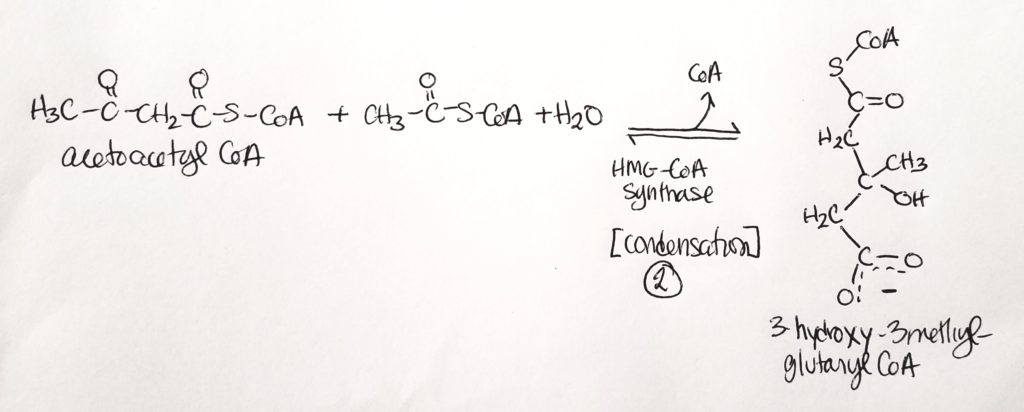
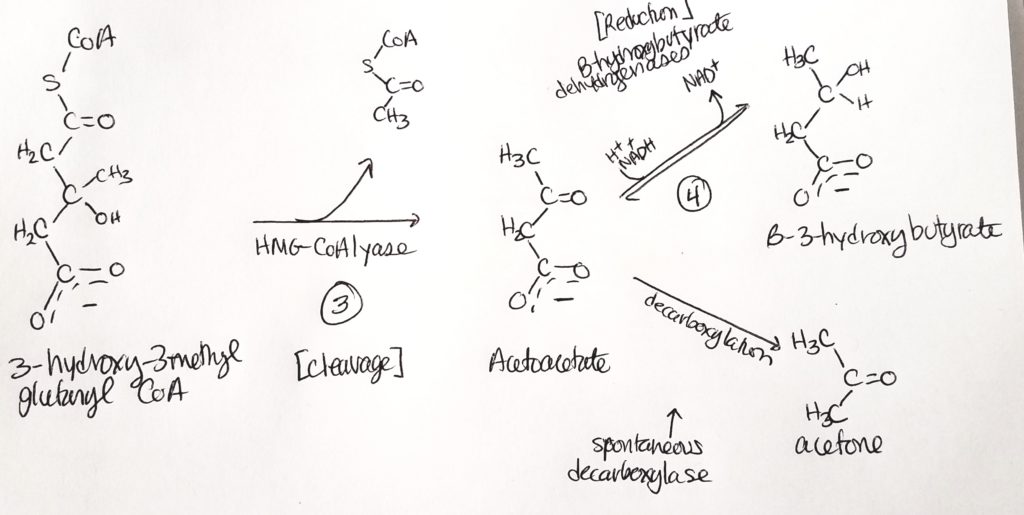
Step 1. Condensation reaction. Sticks two acetyl CoA together.Step 2. Another condensation reaction. Use water. Stick a third acetyl CoA onto the chain.Steps 3 & 4. The products are acetone (not useful and can just breathe it out) and B-3-hydroxybutyrate.
B-3-hydroxybutyrate is the dominant product and is useful for a source of CoA.
Step 1. Two acetyl CoA get joined into 1 acetoacetyl CoA. This is a condensation reaction. CoA is a leaving group (and one CoA stays).
Step 2. Acetoacetyl CoA is joined to another acetyl CoA in a condensation reaction with water. One CoA is a leaving group.
Step 3. One acetyl CoA is cleaved, removing the thiol. We’re left with a four-carbon molecule that B-hydroxybutarate dehydrogenase acts on.
Step 4. End product is B-3-hydroxybutyrate.
All this is going on in the mitochondrial matrix of hepatocytes (liver cells).
So acetoacetate is spontaneously converted sometimes to acetone. Acetoacetate can also spend 1 NADH to form B-3-hydroxybutyrate.
We can breathe acetone out (fruity breath).
Acetoacetate and B-3-hydroxybutyrate can be peed out.
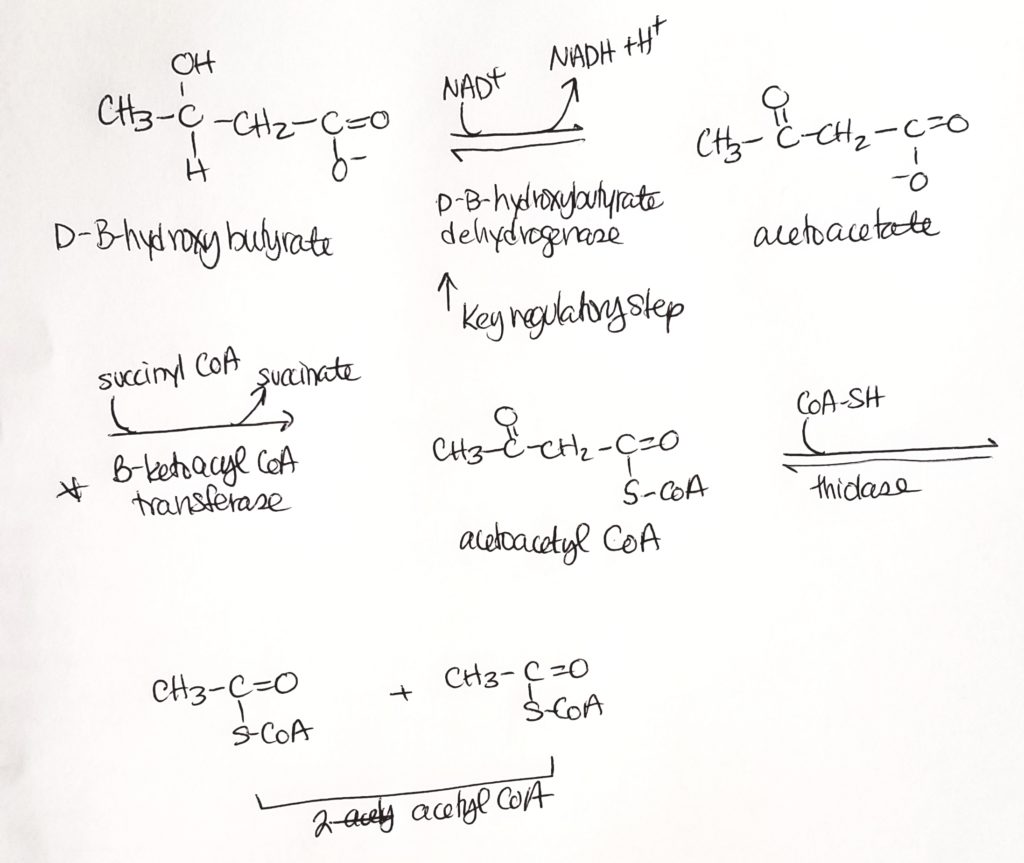
Ketone Body Oxidation (we made them, now we break them).
Ketone body oxidation.
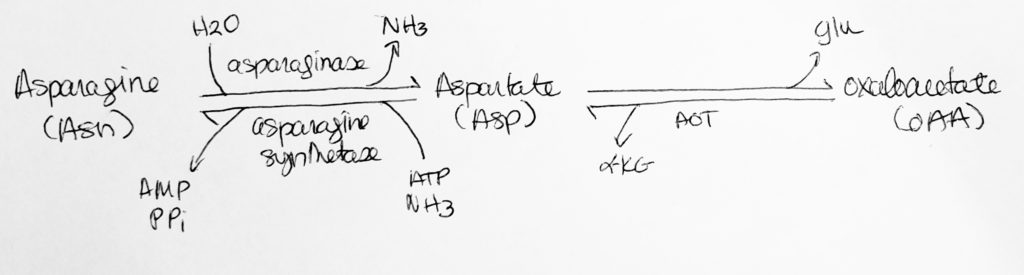
Amino Acid & Nitrogen Metabolism.
Proteins are broken down into amino acids which gets absorbed in the small intestine via intestinal epithelial cells.
Amino acids make proteins and other nitrogen-containing compounds.
The nitrogens that aren’t used for building things get converted to urea and other nitrogenous waste products which get excreted and leave the body.
Amino acids can make glucose.
AA’s can be substrated for FA synthesis.
Amino acids can also be used as a fuel source like the BCAA (branched chain amino acids) that many people use as supplements in muscle-building activities.
Other nitrogen-containing compounds are: ATP, nucleotides, hormones, porphyrin rings.
Key idea: how can we interconvert things, how many ways are there to interconvert things?
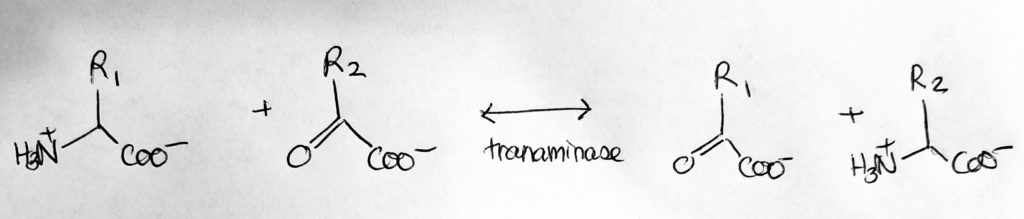
How to move Nitrogen around: Transamination.
Switching partners in transamination.
Transamination. N-exchange.
Catalyst: Transaminases/amino-transferases.
Req: coenzyme PLP aka P5P (vitamin B6).
Take the amine from one molecule and switch it with another group from another molecule. Turns amino acid to alpha-keto-acids and vice versa.
The TCA cycle is responsible for more than 2/3 of ATP production from fuel oxidation.
The conversion of pyruvate into acetyl-CoA takes place inside the mitochondria.
TCA occurs in the matrix of mitochondria (eukaryotes).
Biochemical pathways are different routes that reactants, intermediates, products and etc. can take to lead to different outcomes in order to produce what is needed by the cell/organism. This builds on the concept of basic building blocks make more complex molecules that is needed, and then breaking down the complex molecules back to basic units in ordered to be recycled. Concept of “shuttling”. Intermediates may be recycled-reused and/or may be important to the biosynthesis of other biomolecules.
One of the important goals for the oxidation of FAs, glucose, AAs, acetates and ketones is to convert these materials into acetyl coenzyme A (Acetyl CoA) which is the form that is needed in order to enter the TCA cycle.
Goals is to conserve energy from all the oxidation reactions.
Electrons from intermediates get transferred to NAD+ and FAD.
8 electrons given up from the acetyl group end up in 3 molecules of NADH and 1 FADH2.
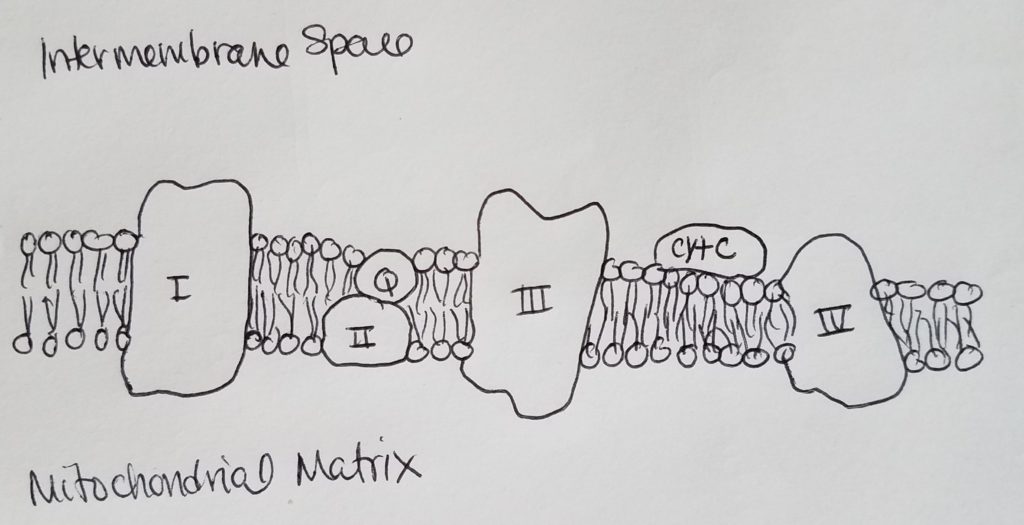
This is important because the carriers NADH and FADH2 give the electrons to oxygen as the final electron acceptor in the electron transport chain (ETC).
Good nutrition plays an important role. This is what the TCA needs: lots of vitamin and minerals; niacin (NAD+); riboflavin (FAD) and flavinmononucleotide; pantothenic acid (coenZ A); thiamin; Mg 2+, Ca 2+, Fe 2+, phosphate.
Sources of Acetyl-CoA include (but not limited to): beta-oxidation of fatty acids such as palmitate; breakdown of ketone bodies beta-hydroxybutyrate and acetoacetate; acetate (from diet or ethanol oxidation); glucose/carbohydrates oxidized to pyruvate; alanine and serine can also be oxidized to pyruvate.
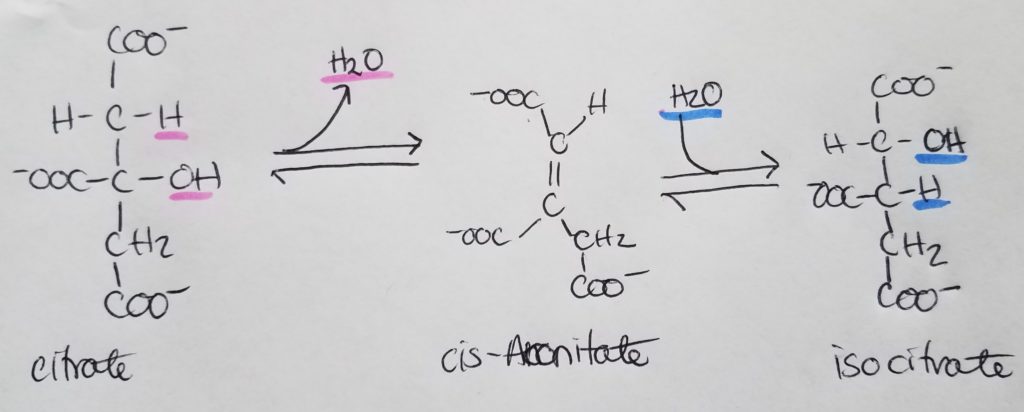
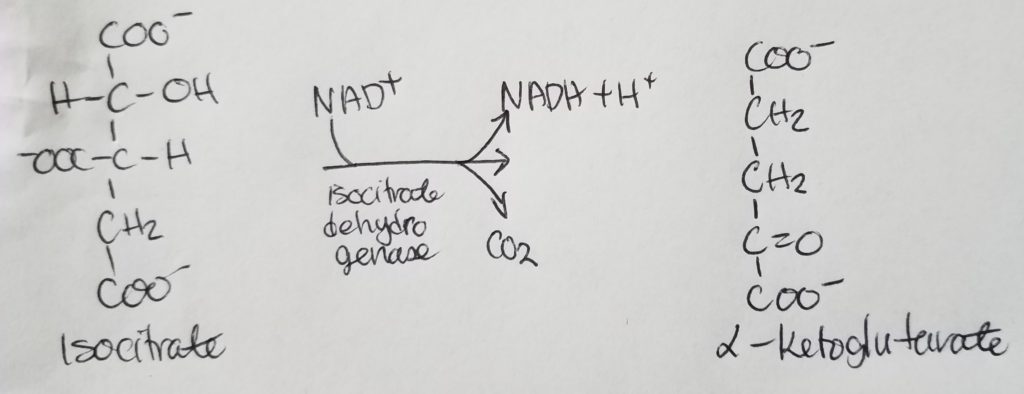
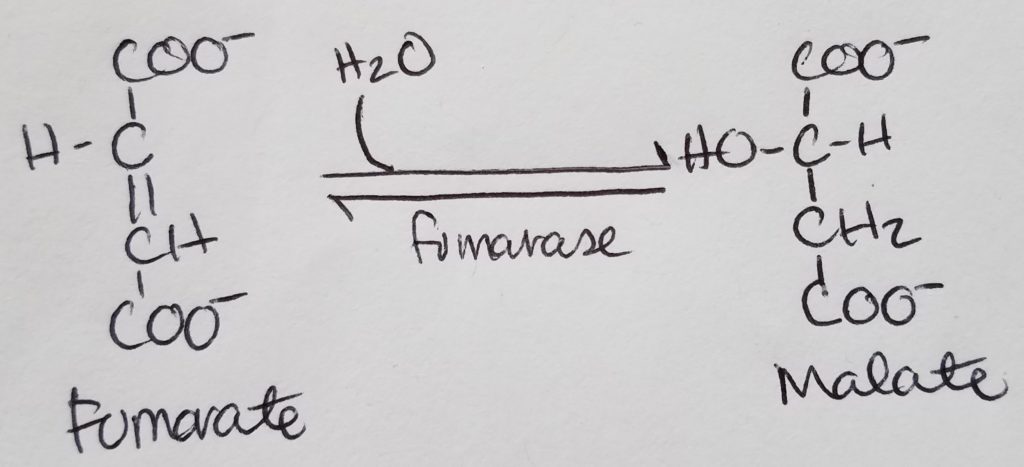
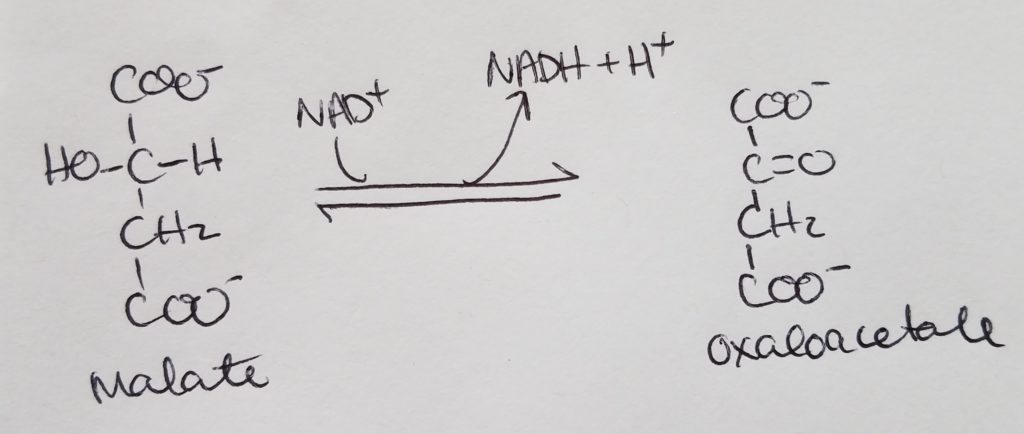
Regulatory steps tend NOT to be reversible (with the exception of step 8, malate <–> oxaloacetate).
Quick Redox Review.
LEO, Lose Electrons Oxidation. Gain oxygen or lose hydrogen.
GER, Gain Electrons Reduction. Lose oxygen or gain hydrogen.
*The more multiple bonds, the greater degree of oxidation.
In biochem, it’s not as “obvious” to see how the electrons flow and what is oxidized and what is reduced.
Sometimes it helps to look at the number of bonds and how the bonds change.
If A is losing electrons/bonds, then it is getting oxidized (it is being oxidized). A’s role is the reducing agent.
If B is gaining electrons/bonds, then it is being reduced. B’s role is the oxidizing agent.
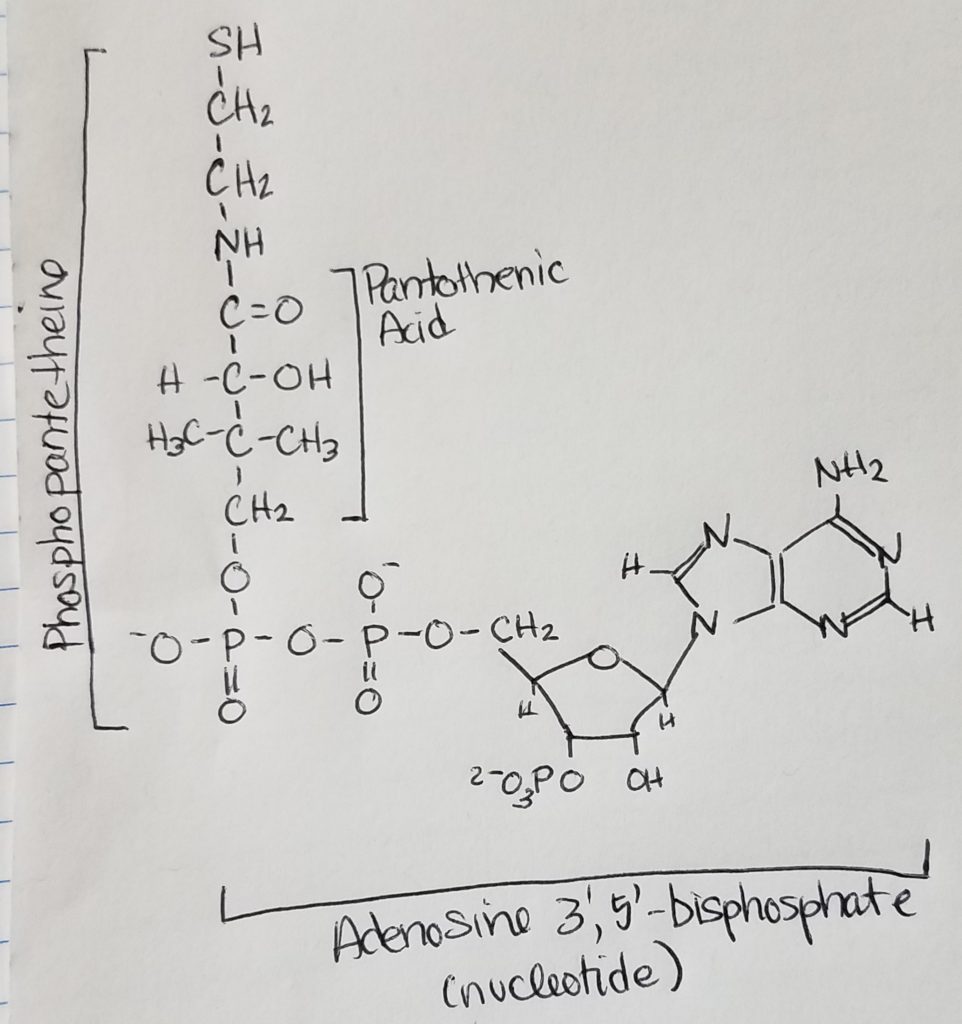
Acetyl CoA.
Examining Acetyl CoA, 2 main structural parts are easily recognizable: phosphopantetheine chain and nucleotide.
The phosphopantetheine chain has -SH thiol group (can form thioesters with acyl groups) at the end of the pantothenic acid.
The nucleotide is adenosine 3′, 5′ -biphosphate.
The CoA-S-(C=O)-R helps to activate fatty acid or acetyl group.
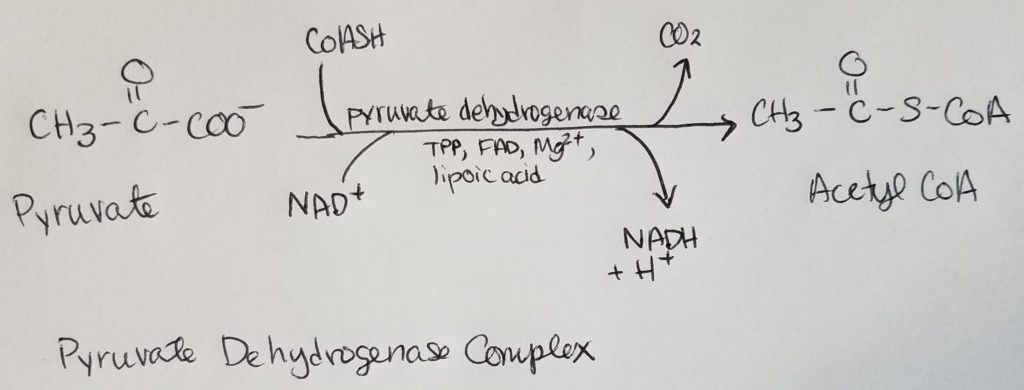
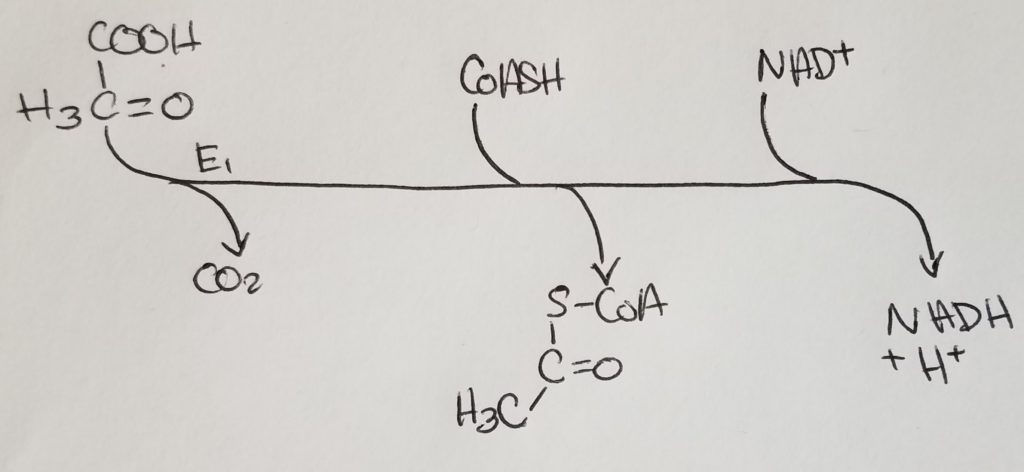
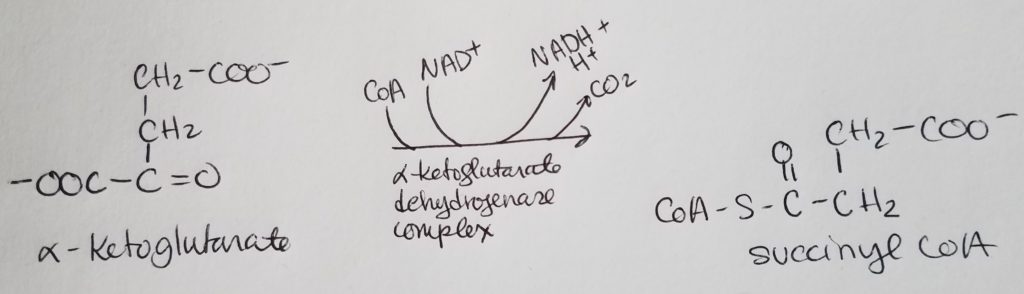
Pyruvate Dehydrogenase Complex (PDHC/PDC).
From the alpha-ketoacid dehydrogenase complex family.
“Synthases” generally work by catalyzing the condensation reaction of 2 organic molecules to form a C-C bond when no high-energy phosphate bond energy is available.
“Synthetase” (note the spelling looks a lot like “synthase”) are enzymes that DO need the high-energy phosphate bond energy to do their work.
*Oxaloacetate is regenerated w/each turn of this cycle.
The condensation of Acetyl-CoA and oxaloacetate (OAA) is irreversible .
Acetyl-CoA can come from: palmitate, acetoacetate, glucose, pyruvate, alanine, and ethanol (PPAAGE). However, the major source is oxidative decarboxylation of pyruvate via pyruvate dehydrogenase complex (PDHC).
Step 1. Citrate synthase reaction.
STEP 2. Isomerization of Citrate.
Citrate (a tricarboxylate acid) is rearranged to isocitrate.
This is a rate-limiting step as isocitrate dehydrogenase is allosterically activated by ADP and Ca+2 and inhibited by ATP and NADH.
Step 3. Isocitrate dehydrogenase reaction.
STEP 4. Oxidation of Alpha-Ketoglutarate.
Alpha-ketoglutarate undergoes oxidative decarboxylation to form succinyl-CoA.
Reactants: alpha-ketoglutarate, CoASH.
Enzymes: alpha-ketoglutarate dehydrogenase complex, protein aggregate (contains conenzymes TPP or thiamine pyrophosphate, lipoic acid, FAD).
Products: succinyl CoA, CO2, NADH + H+.
Irreversible reaction.
Regulation: -NADH, +Ca+2.
CO2 is released from one of the carboxyl groups of alpha-ketoglutarate.
Second NADH is released.
Step 4. Oxidation of alpha-ketoglutarate.
STEP 5. Formation of Succinate.
Succinyl-CoA >> succinate thiokinase >> Succinate
Reactants: succinyl CoA, GDP + Pi.
Enzyme: succinate thiokinase (cleaves thioester bond and the bond energy is used to make GTP from GDP and Pi).
Products: succinate, GTP, CoASH.
Reversible reaction.
Note that guanosine diphosphate (GDP) gets phosphorylated to GTP. GTP and ATP are interconvertible via nucleoside diphosphate kinase: GTP + ADP <–> GDP + ATP
Substrate-level phosphorylation: forming a high-energy phosphate bond (with none having preexisted) from molecular O2 and NOT from oxidative phosphorylation.
Step 5. Formation of succinate.
STEP 6. Formation of Fumarate.
Succinate >>succinate dehydrogenase>> Fumarate
Reactants: succinate, FAD.
Enzyme: succinate dehydrogenase.
Products: fumarate, FADH2.
Reversible reaction.
The coenzyme FAD gets reduced to FADH2.
Succinate dehydrogenase is the only enzyme in the TCA that is in the inner mitochondrial membrane.
STEP 7. Formation of Malate.
Fumarate >>fumarate hydratase>> Malate
Reactants: fumarate, water.
Enzyme: fumarase.
Product: Malate.
Reversible reaction.
This is a hydration reaction.
Step 7. Formation of malate.
STEP 8. Formation of Oxaloacetate.
Malate >>malate dehydrogenase>> Oxaloacetate
Reactants: malate, NAD+.
Enzyme: malate dehydrogenase.
Products: oxaloacetate + NADH + H.
Reversible reaction AND a regulatory step.
Regulation: -NADH.
This step makes the third NADH.
Step 8. Formation of oxaloacetate.
Summary of TCA Step 1-8.
TCA Regulation.
The rate of TCA is regulated to correspond to the rate of ETC.
ETC is regulated by the ratio of ATP:ADP and the rate of ATP usage.
ATP Rate of Usage Feedback: 1. phosphorylation state of ATP (ratio of ATP:ADP) 2. reduction state of NAD+ (ratio of NADH:NAD+)
In the cell and also in mitochondria, the pools of total adenine and the pools of total NAD are fairly/relatively constant.
Citrate Synthase Regulation.
Has no allosteric regulators.
Rate is controlled by concentration of oxaloacetate and the concentration of citrate (product inhibitor and competitor of oxaloacetate)
Malate-oxaloacetate equilibrium favors malate. Oxaloacetate concentration is low inside mitochondria.
As the NADH:NAD+ ratio increases, the oxaloacetate:malate ratio also increases.
Activation of isocitrate dehydrogenase decreases the concentration of citrate, suppressing the inhibitory effect of citrate synthase.
Liver NADH:NAD+ ratio helps determine if Acetyl-CoA enters the TCA or another pathway for ketone production.
Isocitrate Dehydrogenase Regulation.
Isocitrate dehydrogenase is made up of 6 subunits.
Is one of the rate-limiting steps in TCA.
Allosterically activated by ADP.
Also activated by Ca+2. The release of Ca+2 from the sarcoplasmic reticulum may provide additional activation.
Inhibited by NADH.
When ADP is absent, the subunits bind to each other and are converted to an active conformation.
When ADP is present, all the subunits are in active conformation enabling isocitrate to bind more easily and readily.
A small change in the concentration of ADP can significantly affect this step.
Alpha-Ketoglutarate Dehydrogenase Regulation.
Alpha-ketoglutarate is a complex.
It isn’t allosterically regulated.
It is product-inhibited (negative feedback) by NADH and succinyl-CoA (and maybe GTP as well).
Also activated by Ca+2. The release of Ca+2 from the sarcoplasmic reticulum may provide additional activation.
TCA Intermediates Regulation.
TCA regulation ensures that the rate of NADH generation is sufficient to maintain ATP homeostasis, AND regulates the concentration of all the intermediates.
The Electron Transport Chain (ETC) & Oxidative Phosphorylation.
Chemiosmotic Model of ATP Synthesis.
ETC occurs in the inner mitochondrial membrane, the site of oxidative phosphorylation via ATP synthase.
A series of oxidative reactions using oxygen as the final electron acceptor, release water and carbon dioxide.
The intermediates of this oxidative series donate their electrons to coenzymes, adenine dinucleotide (NAD+), and flavin adenine dinucleotide (FAD). The reduced NADH and FADH2 have lots of energy stored in their bonds.
As electrons are shuttled down this chain, they lose their free energy. This energy gets redirected to transport H+ (protons) from the mitochondrial matrix across the inner membrane of the mitochondria to cytosolic side thus causing an H+ gradient enabling the production of ATP from ADP + inorganic phosphate, Pi.
This “proton pump” creates an electrochemical gradient. This is key.
ATP synthase has a pore from the inner membrane to the headpiece sticking out in the matrix. Protons are pushed through this pore changing the conformation of the headpiece and this causes the simultaneous release of ATP at one site and the formation of ATP from ADP + Pi at another site.
Mitochondria.
Inner mitochondrial membrane, rich in proteins, is impermeable to most small ions (including H+) and molecules like ADP, ATP, pyruvate, etc. The mitochondria need specialized carriers to transport goods inside. Cristae (convolutions) help to increase the surface area.
The inner membrane has 4 separate complexes which are part of the ETC.
ETC has 3 large protein complex I, III, & IV spanning the inner mitochondrial membrane.
All members of the ETC, except CoQ (lipid-soluble quinone), are proteins.
ATP that’s made is actively transported into the intermembrane space by adenine nucleotide translocase (ANT).
Yields 30-32 ATP.
Matrix maintains a low concentration of H+, high pH.
Intermembrane space maintains a high concentration of H+ low pH.
Proton pumps pump H+ from the matrix to the intermembrane space. Because this is against the concentration, it takes energy/work to maintain this potential gradient.
Electron Carriers.
NAD+ (nicotinamide adenine dinucleotide). Related to vitamin B3, niacin. Indirectly produces 2.5-3 ATPs. NADH –> NAD+ + H + 2e-
FAD (flavin adenine dinucleotide). Related to vitamin B2, riboflavin. Its electrons are at a lower energy state. Indirectly produces 1.5-2 ATPs.
FMN (flavin mononucleotide). Vitamin B2, riboflavin. A prosthetic group, a non-protein molecule that is needed for the function of a protein.
2e- + H+ + 1/2O2 = water (this is the reduction of oxygen to water, or the oxidation of NADH to NAD+)
Ubiquinone (Q) carries electrons from complex I and complex II to complex III. It is lipid-soluble and moves in the hydrophobic core of the membrane. Q carries pairs of electrons (2e-).
Cytochrome C. Carries electrons from complex III to complex IV. Cytochrome C can carry only one e- at a time.
Cytochrome B.
Cytochrome A.
Cytochrome A3.
Complex I and Q.
NADH carries 2e- to complex I.
Complex I is the entrypoint for NADH.
Complex I is made of FMN (vitamin B2) and Fe-S.
NADH dehydrogenase is the enzyme in complex I.
Complex I pumps 4 H+ into the intermembrane space.
Ubiquinone (Q) takes the 2e- and shuttles them to cytochrome C which shuttles them to complex III.
Complex II (succinate dehydrogenase).
Complex II is the entry point for FADH2.
FADH2 ‘s electrons are dropped off and Q shuttles them to complex III.
Q, a mobile electron carrier like a “taxi”, is reduced to QH2.
Complex II is bound to the membrane.
Complex II is not a pump.
Complex III (cytochrome oxidoreductase).
Complex III is composed of: Fe-S, cytochrome b, Reiske centers (2Fe-2S), cytochrome c1.
Complex III pumps 4 H+ to the intermembrane space.
The electrons get passed to complex IV via cytochrome c. Cytochrome c can carry only one e- at a time (not 2e-).
Electrons get passed from cytochrome b to Fe-S to cytochrome c1.
Complex IV.
Complex IV is made of cytochromes c, a, and a3.
Complex IV has 2 heme groups per cytochromes a and a3. An oxygen molecule is bound very tightly between the iron and copper ions until the oxygen can be totally reduced at which point it picks up two H+ from the surrounds for the creation of water.
2H+ gets pumped out to the intermembrane spae.
Summary of ETC.
So thus far, the main purpose of ETC is two-fold: maintain the [H+] concentration gradient (high [H+] in the intermembrane space, and low [H+] in the matrix), and the shuttling of e- from a higher energy state to lower energy state where oxygen is the final electron acceptor and is expelled by binding it to two H+ to form water. Complexes I, III, and IV are proton pumps while complex II is like a proton funnel.
Chemiosmosis & ATP Synthase.
Chemiosmosis is when the movement of ions down their electrochemical gradient is harnessed “to do work”. In this case, “work” is putting ADP and Pi together to form ATP.
This process accounts for more than 80% of the ATP produced in the human body.
ATP synthase is a proton channel (the only kind in the intermembrane space of mitochondria) allowing H+ from the intermembrane space to flow down their concentration gradient back into the matrix.
ATP synthase is like a water-wheel or wind/water turbine. For every four H+ that flows through ATP synthase (from the intermembrane space to the matrix), one ADP + Pi bond can be “built” resulting in ATP.
This process occurs in the cytosol and doesn’t require oxygen (can work in the presence of oxygen or without oxygen).
There are 2 stages. Stage 1 is the “spending” stage where ATP is spent. Stage 2 is the “money-making” stage where we make some “ATP money” back.
In the larger picture, the real advantage of glycolysis is making that pyruvate, then converting the pyruvate into acetyl CoA (in the mitochondria) and entering the TCA cycle and ETC (where the most amount of ATP is made…like winning the lottery).
Stage 1. Step 1. Glucose to Glucose 6-phosphate.
This step is a commitment. Once a phosphate groups is attached to glucose, glucose cannot leave the cell.
Stage 1. Step 2.
Stage 1. Step 3.
This is the primary regulatory step for glycolysis.
Fructose 1,6-bisphosphate is not a “real intermediate” (meaning it doesn’t act as an “intermediate”) but plays a more regulatory role in that its presence will either inhibit or promote an action.
PFK1 is a rate-limiting enzyme via allosteric regulation.
Inhibited by high concentrations of ATP.
Inhibited by citrate concentrations.
Promoted/stimulated by high concentrations of AMP (adenosine monophosphate).
Promoted/stimulated by high concentrations of fructose 2,6-bisphosphate.
If citrate appears in the cytosol, it can “leak out” and slow down the TCA cycle because an abundance of citrate indicates that the energy needs requirements are met–we have adequate energy/fuel. Citrate builds up in the mitochondrial matrix and “leaks” out into the cytosol.
Stage 1. Step 4.
A 6-carbon molecule splits into two 3-carbon molecules which are isomers of each other. The only form that will continue on in the glycolysis process is glyceraldehyde 3-phosphate (GAP).
The two 3-carbon isomers “flip” configuration back-and-forth via triose phosphate isomerase. This is noted in the next step 5.
Stage 1. Step 5.
While these two isomers coexist with equal likelihood, the only form that will continue on in the glycolysis process is glyceraldehyde 3-phosphate.
Stage 2. Step 6.
This is the only step where oxidation occurs.
This step is a redox reaction.
Stage 2. Step 7.
Substrate level formation of ATP.
Note the resonance structure of 3-phosphoglycerate.
Stage 2. Step 8.
Mutase phosphate on carbon 2.
Stage 2. Step 9.
Stage 2. Step 10.
Substrate level ATP formation.
Inhibited by high concentration of ATP, product-inhibition.
Promoted/activated by fructose 1,6-bisphosphate.
Recap.
In Stage 1, two ATP was “spent” or -2 ATP.
In Stage 2, 4 ATP were created.
Net ATP = 2.
In Stage 2, 2 NADH were created.
In Stage 2, 2 molecules of water were created.
In Stage 2, 2 molecules of pyruvate were created.
Regulation of Glycolysis.
Glycolysis is regulated at 5 enzymatic areas (and their corresponding step): hexokinase; phosphofructokinase; glyceraldehyde 3-phosphate dehydrogenase; phosphoglycerate kinase; and pyruvate kinase.
Hexokinase (glucose to glucose 6-phosphate): inihibited by high levels of glucose 6-phosphate (product inhibition which is a form of negative feedback).
Phosphofructokinase (fructose 6-phosphate to fructose 1,6-bisphosphate): most important as a rate-limiting step in mammalian glycolysis; this is the first committed step which means that if we make the product for this step, we are committed to the rest of the glycolytic pathway. Fructose 1,6-bisphosphate is the product. Inhibited by: high ATP concentrations; high citrate concentrations. Activated by: high AMP concentrations; high fructose 2,6-bisphosphate (formed in the FED state when glucose is abundant). Fed/absorptive state is up to 4 hours after a meal.
Pyruvate kinase (phosphoenolpyruvate to pyruvate): inhibited by high ATP concentrations; activated by high fructose 1,6-bisphosphate concentratoins.
Alternate Paths for Pyruvate.
Glycolysis makes pyruvate.
From there, pyruvate can be used in many different pathways: alcohol fermentation (anaerobic microbial/bacterial process); lactate fermentation (anaerobic); aerobic respiration (conversion of pyruvate to acetyl CoA, TCA cycle, ETC).
Alcohol Fermentation.
Results in 2 ATP.
Anaerobic pathway.
Lactate Fermentation.
Results in making 2 ATP.
Anaerobic pathway.
Occurs in muscle cells under anaerobic conditions.
Entrypoints of Other Sugars.
Fructose (mobilized from adipose tissue) enters glycolysis at fructose 6-phosphate.
Galactose enters glycolysis at glucose 6-phosphate.
Gluconeogenesis.
Gluconeogenesis is the process by which pyruvate is converted to glucose; glucose is generated from non-carbohydrate sources (lactate, amino acids, fatty acids).
If there’s an increase in glycolytic activity, gluconeogenesis is suppressed.
If there’s a decrease in glycolytic activity, gluconeogenesis is promoted/activated.
Gluconeogenesis is not “reverse glycolysis” because glycolysis contains 3 irreversible steps. SO, we need to find a “workaround” for those 3 irreversible steps in glycolysis.
Gluconeogenesis is a highly aerobic pathway!
Roadblock 1. How can we get to phosphoenol pyruvate from pyruvate?
Side note: lactate can be converted to pyruvate.
Let’s start with pyruvate. We want to convert pyruvate to phosphoenol pyruvate so that we can reuse and follow most of the reversible steps in glycolysis (don’t reinvent the wheel when you don’t need to).
Pyruvate can be converted to oxaloacetate (OAA) via enzyme pyruvate carboxylase and using 1 ATP.
As a side note: amino acids can be converted to OAA and enter the pathway here.
Then we can use GTP and enzyme PEPcarboxylase to convert OAA to phosphoenol pyruvate (at which point we can join the reversible steps in glycolysis).
Roadblock 2. How can we get from fructose 1,6-bisphosphate to fructose 6-phosphate?
We can use enzyme fructose 1,6-bisphosphotase to work-around this roadblock (irreversible reaction in glycolysis) to form fructose 6-phosphate. From fructose 6-phosphate, we can use the reversible steps of glycolysis. Again, don’t reinvent the wheel!
Roadblock 3. How can we get from glucose 6-phosphate back to glucose?
No problem…we just wanna get back to good ole regular glucose!!
We use this slick enzyme glucose 6-phosphotase to convert glucose 6-phosphate back to glucose.
Cori Cycle (aka Lactic Acid Cycle).
In the muscle, glucose can make pyruvate which can be converted to lactate which can enter the bloodstream, which can enter the liver to be converted to pyruvate and back to glucose.
Glycolysis happens in the muscles.
Gluconeogenesis happens in the liver.
When oxygen levels are low, anaerobic glycolysis happens.
We need to regenerate NAD+.
Side note: the heart muscle can also use lactate as an energy source.