Last edited: 08.08.2019
See Appendix A Amino acid abbreviations; Appendix B Glucogenic, Ketogenic, and Glucoketogenic Amino acids; Appendix C 20 Amino Acids to Know Drawn at Physiological pH 7.4.
Review of Macromolecules and Functional Groups.
- What is a monomer? A monomer is a base unit of something. A base unit is something that cannot be broken down further without losing is character, traits, physical/chemical properties, behavior, etc. A monomer of a chocolate bar (a polymer) is one square of chocolate. Several squares of chocolate (monomers) make up that one large chocolate bar (polymer).
- What is a polymer? A polymer is a larger compound built up from base units of monomers.
- Examples of polymers and monomers.
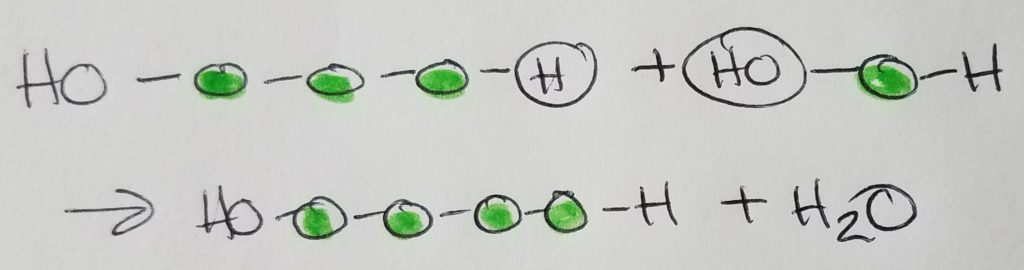
Condensation (dehydration) synthesis.
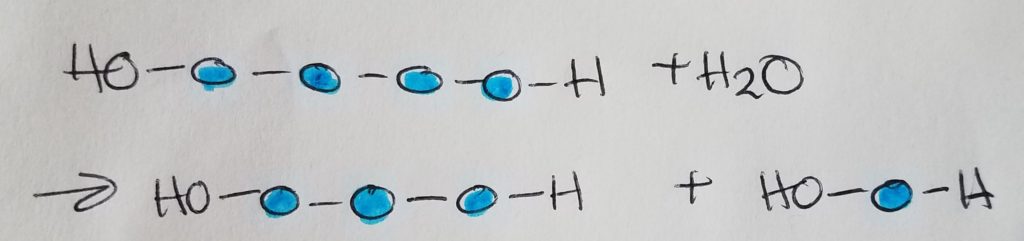
Hydrolysis.
Carbohydrates.
A. Structure.
A sugar monomer is a single sugar unit called a monosaccharide. Two monosaccharides make up a disaccharide via glycosidic linkage. Sucrose = glucose + fructose. Maltose = glucose + glucose.
Glycosidic linkages are condensation/dehydration reactions in which H2O is a product (is produced in the reaction). The formula for a typical sugar is CnH2nOn.
Sugars may be aldoses (aldehyde group at top) or ketoses (ketone group at top). On a Fischer projection, L-sugars have the hydroxyl group on the left of the last chiral carbon (carbon farthest away from the aldehyde or ketone group). D-sugars have the hydroxyl group to the right of the last chiral carbon. The human body almost exclusively uses D-sugars.
Sugars can have the same molecular formula but still be different due to stereochemistry. Galactose and glucose can have the same molecular formula. They are different sugars because they are arranged differently. It’s like having 5 red legos and 5 blue legos; you can put them together in many different combinations.
B.Function.
Examples of polysaccharides: starch (plant energy storage), cellulose (fiber-like used for plant cell walls), glycogen (animals’s energy storage in muscles and liver), chitin (exoskeletons and fungal cell walls). Example function of carbohydrates and used for energy storage and structural support.
Proteins.
A. Structure.
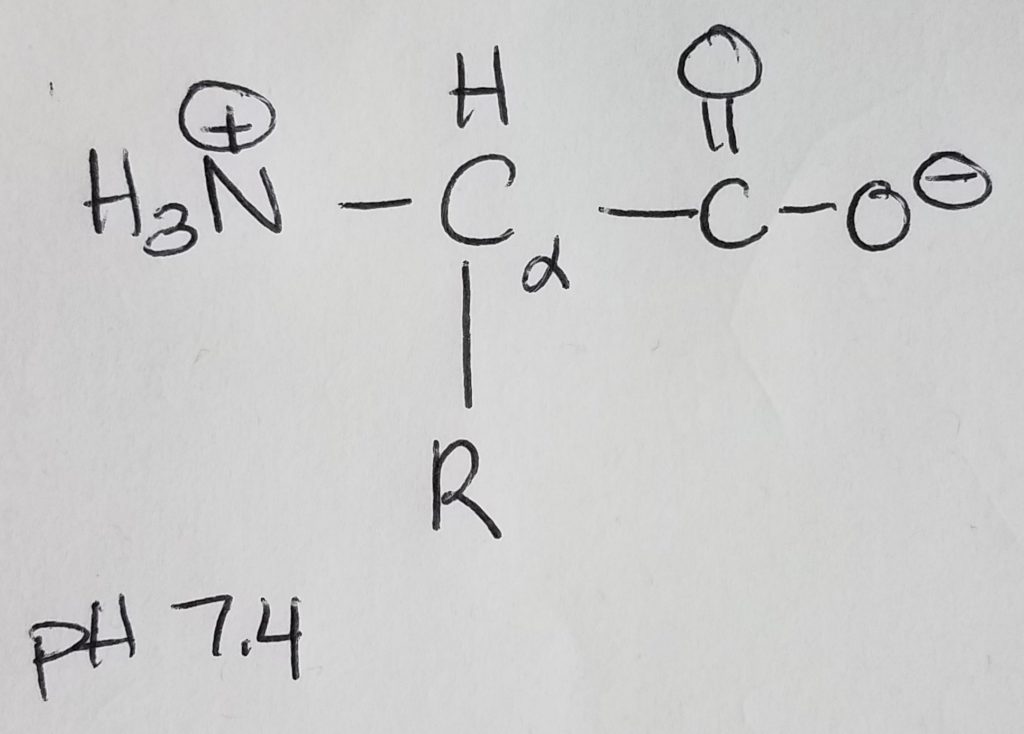
Amino acids are monomers for proteins which are 1+ polypeptide chains (polymer). 2 AA’s are joined via peptide bonding. Polypeptide chains can get longer and longer and you can put multiples of them together to form complex molecules. Once AA’s become part of a chain they are called “residues”. AA’s are made up of: an amine group, a carboxylic acid group, a hydrogen at the alpha-carbon, and a R-sidechain.
At physiological pH of 7.4, the amino group is protonated (+NH3) and the carboxylic acid group is deprotonated (COO-). Because the molecule has a dual charge, it’s called a zwitterion. The charged amino group at the leftmost position of the chain is called the N-terminus; the carboxylate ion at the rightmost position of the chain is called the C-terminus. AA’s are joined together to form a chain via peptide bonding.
Remember that if the pH < pKa, then that group will be protonated (e.g. +NH3, COOH). If pH > pKa, then that group will be deprotonated (e.g. NH2, and COO-). Physiological pH is 7.4; pKa is ~9.0 for amines; pKa is ~4.75 for carboxylic acid. Histidine’s pKa is very close but a little on the basic side at physiological pH.
Amino acids have stereochemistry (they have mirror images).
The “L” designation in L-amino acids denotes that the zwitterion is oriented with the protonated amine group at the left and the carboxylate ion on the right. The human body uses L-amino acids with the exception of glycine which is achiral. This is also important because the L stereochemistry is what our body uses in ligand-receptor binding (e.g. enzymes).
The alpha-carbon is the carbon directly bonded to the carboxylic acid group. The alpha amine is the amine group directly bonded to the alpha carbon.
Peptide bonding is when the carboxylate end of one AA covalently bonds with the charged amino end of another AA giving off a water molecule. Peptide bonding is a special form of dehydration synthesis (condensation reaction) between two amino acids. A more general term for peptide bonding is amide bonding. Bonding sequence matters. If amino A is bonded to amino B and then to amino C, the charged amino group of A is retained. In the order A-B-C, the carboxylate ion of amino C is retained. Bonding order matters. A-B-C is not the same as B-C-A.
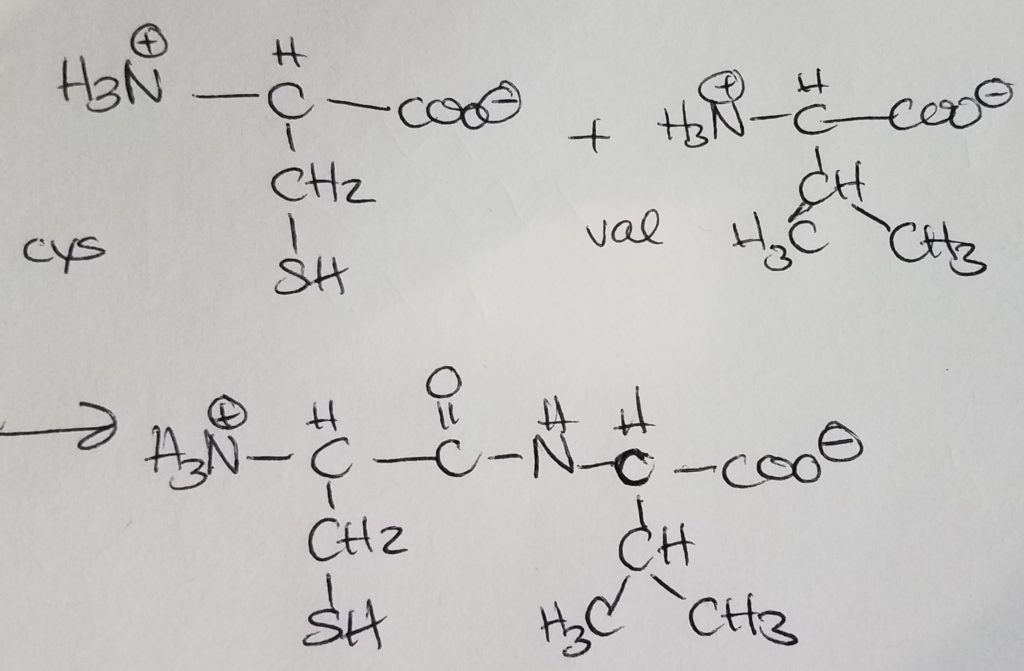
Proteins have primary, secondary, tertiary, and quaternary structures.
Primary structure is characterized by an unique sequence of amino acids in a polypeptide. Structure and function go hand in hand. Any tiny change in structure could impact the function of the protein.
Secondary structure is characterized by repeated folding of the polypeptide BACKBONE. The keyword is backbone. Hydrogen bonds (H-bonds) stabilize peptide bonds. The alpha helix and B-pleated sheets (parallel or antiparallel). Antiparallel configuration is more stable as steric and angle strain.
http://www.chem.ucla.edu/~harding/notes/strain_01.pdf
https://chem.libretexts.org/Bookshelves/Organic_Chemistry/Supplemental_Modules_(Organic_Chemistry)/Alkanes/Properties_of_Alkanes/Cycloalkanes/Ring_Strain_and_the_Structure_of_Cycloalkanes
Tertiary structure is characterized by lots more globular folding and interactions between R-sidechains/groups (H bonds, ionic bonds, sulfhydral bonds, disulfide bridges, salt bridges). This is where the polar/nonpolar, acidic/basic, etc. properties of amino residues becomes an important consideration.
Quaternary structure is characterized by 1+ separate tertiary structures assembling together to form a more complex molecule. Often the “core” or pockets created may hold inorganic ions and some of the gaps created may be ligand-receptor sites. The act of binding and releasing can cause conformational changes altering the function of the protein.
B. Function.
Amino acids may be classified as essential (ones the human body cannot make and must come from exogenous sources). Nonessential amino acids are ones the human body can make.
Amino acids may be classified based on the polar/nonpolar characteristics of the sidechain: polar, nonpolar; acidic/basic/uncharged or neutral.
Amino acids may be classified based on aromatic or aliphatic (structural comparison).
Amino acids may be classified based on what they can make: glucogenic (make glucose); ketogenic (make ketones); glucoketogenic (make both glucose and ketones).
Proteins can have all sorts of functions: acting as enzymes, structural support, antibodies, cell signalling, transport, and movement.
See Appendix A Amino acid abbreviations; Appendix B Glucogenic, Ketogenic, and Glucoketogenic Amino acids; Appendix C 20 Amino Acids to Know Drawn at Physiological pH 7.4.
Lipids.
A. Structure.
A functional unit of lipids is a triglyceride which is a glycerol (trihydric alcohol) and fatty acids (acyl groups which can be saturated or unsaturated long hydrocarbon with a carboxylic acid head. The carboxylate head bonds with the hydroxyl (of the glycerol) via ester linkages. The fatty acids that get attached to the glycerol do not have to be the same. Triglycerides are amphipathic (the key to this structure is its hydrophilic and hydrophobic duality).
Phospholipid = glycerol + 2 FA chains + phosphate + head-group. The key to this structure is its hydrophilic and hydrophobic duality. This is important to cell membranes, micelles, etc.
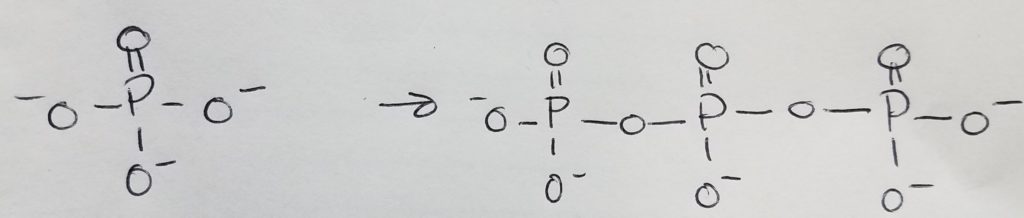
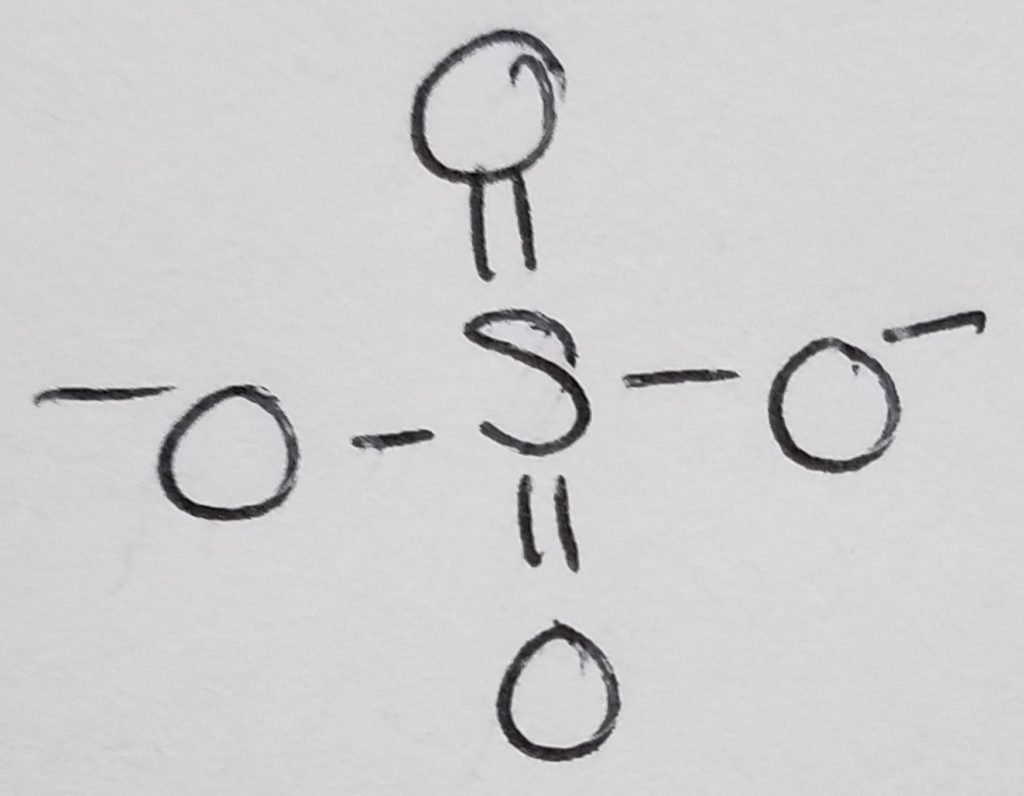
Waxes = 2 long hydrocarbon tails connected via ester bond.
Steroids = 4 carbon rings with no fatty acid tails.
http://www.biologie.ens.fr/~mthomas/L3/intro_biologie/2-sucres-lipides-acides-nucleiques.pdf
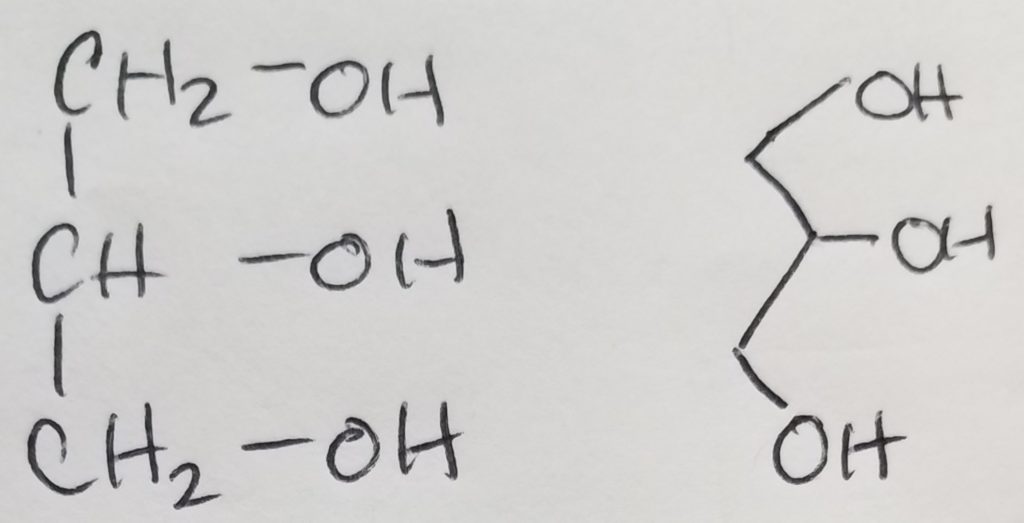
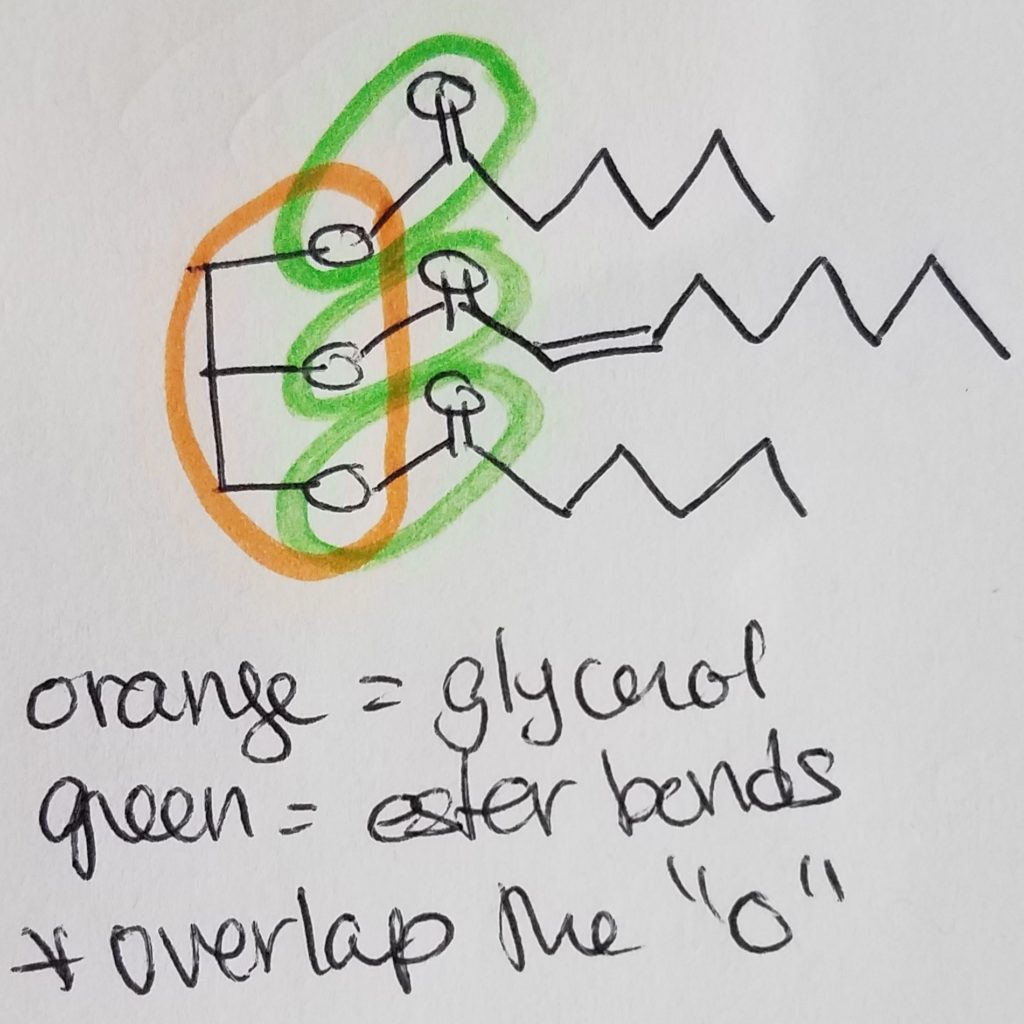
**Circle the ester bond(s) and circle the glycerol component. BE CAREFUL that the ester bonds will overlap with the glycerol oxygen.
B. Function.
Some functions include (but not limited to): creating a barrier; insulation; protection; energy storage; hormones, carriers (e.g. fat soluble vitamins) and signalling.
Nucleic Acids.
A. Structure
Nucleotides are the monomers for nucleic acids. A nucleotide = pentose sugar (e.g. deoxyribose or ribose) + phosphate (mono, di, or tri) + nitrogenous base. “Deoxyribose” just means that the second carbon in the ring does not have a hydroxyl group (i.e. carbon 2 is bonded to two hydrogens). A nucleoSide = pentose sugar (e.g. deoxyribose or ribose) + nitrogenous base = nucleoTide without the phosphates.
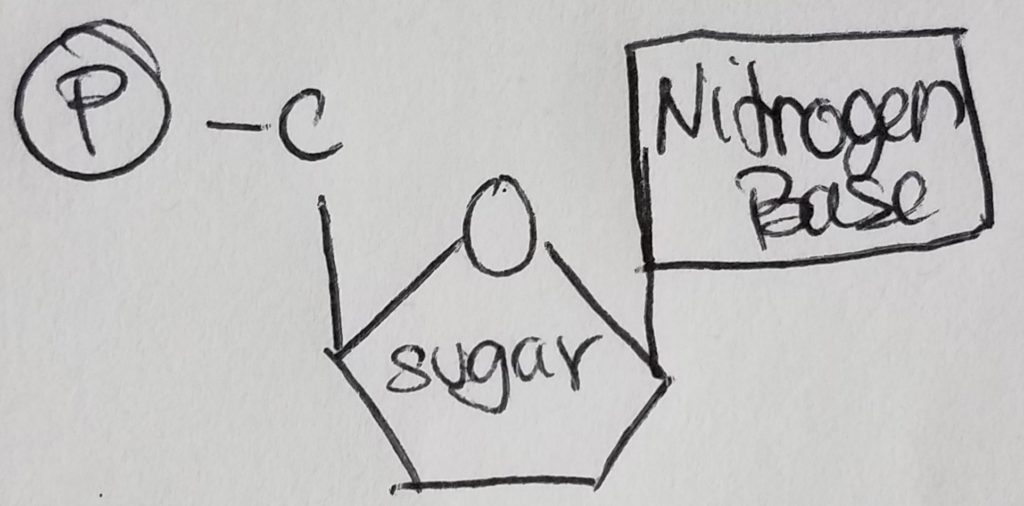
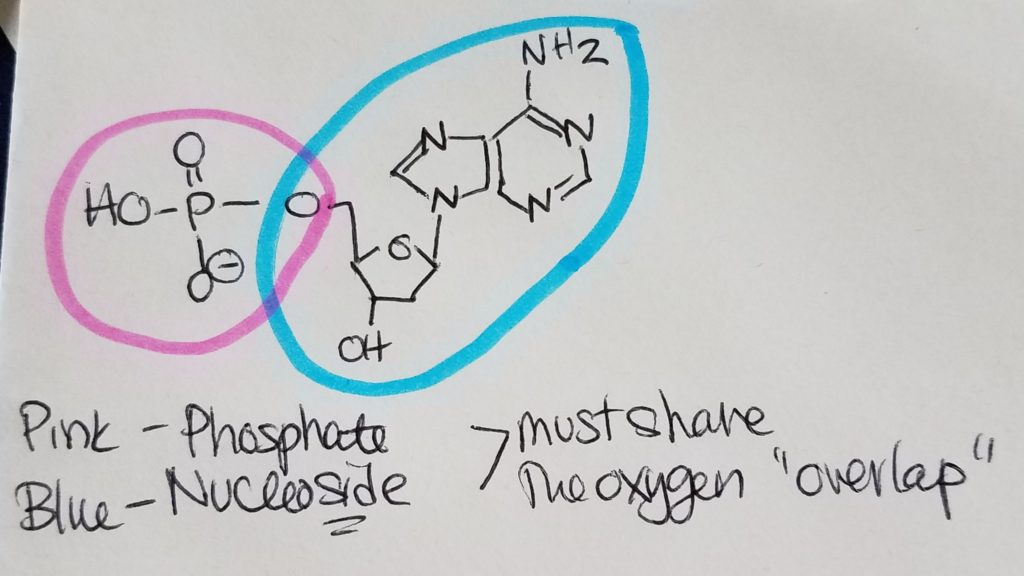
The pentose sugar is bonded to the nitrogenous base via N-glycosidic bond. The phosphates are bonded to the pentose sugar via phosphoester bonding.
https://chem.libretexts.org/Courses/Sacramento_City_College/SCC%3A_Chem_309_-_General%2C_Organic_and_Biochemistry_(Bennett)/Text/13%3A_Functional_Group_Reactions/13.10%3A_Phosphoester_Formation
The nitrogen bases used are guanine, adenosine, cytosine, thymine, and uracil (DNA pairs are C-G and A-T, RNA pairs are C-G and A-U). Adenine and guanine are purines (5 ring connected to a 6 ring); cytosine, thymine, and uracil are pyrimidines. Base pairs between C and G are stronger due to an extra H-bond.
How to tell them apart?
Cytosine has an amine group bonded to one of the carbons on the ring. Adenosine has a carbonyl group with the carbonyl carbon as part of the ring. Uracil has two carbonyl groups, each with the carbonyl carbon as part of the ring.
Adenine has an amine group hanging off the 6-ring structure; guanine has a carbonyl group with the carbonyl carbon as part of the ring structure.
The nucleotide monomers are connected via covalent bonding carbon 5 of one sugar to the carbon 3 of the other sugar (phosphate group sandwiched inbetween). We call this the 5′ (five prime) position and 3′ (three prime) position. It is a condensation reaction forming a phosphodiester bond between the sugars and phosphate groups (alternating sugar-phosphate-sugar-phosphate etc.) with water given off as a product.
Differences between DNA and RNA.
1. Sugar. DNA has deoxyribose (missing -OH on 2nd carbon); RNA has ribose.
2. Base pairs. DNA’s base pairs are C-G, A-T. RNA’s base pairs are C-G, A-U.
3. # of strands. DNA has two strands in a double helix configuration (H-bonds help to stabilize). RNA is single-stranded.
B. Function.
Nucleic acids are in genetic material like DNA and RNA.
The nitrogen bases used are guanine, adenosine, cytosine, thymine, and uracil (DNA pairs are C-G and A-T, RNA pairs are C-G and A-U). Adenine and guanine are purines (5 ring connected to a 6 ring); cytosine, thymine, and uracil are pyrimidines. Base pairs between C and G are stronger due to an extra H-bond.
How to tell them apart?
Cytosine has an amine group bonded to one of the carbons on the ring. Adenosine has a carbonyl group with the carbonyl carbon as part of the ring. Uracil has two carbonyl groups, each with the carbonyl carbon as part of the ring.
Adenine has an amine group hanging off the 6-ring structure; guanine has a carbonyl group with the carbonyl carbon as part of the ring structure.
The nucleotide monomers are connected via covalent bonding carbon 5 of one sugar to the carbon 3 of the other sugar (phosphate group sandwiched inbetween). We call this the 5′ (five prime) position and 3′ (three prime) position. It is a condensation reaction forming a phosphodiester bond between the sugars and phosphate groups (alternating sugar-phosphate-sugar-phosphate etc.) with water given off as a product.
Differences between DNA and RNA.
1. Sugar. DNA has deoxyribose (missing -OH on 2nd carbon); RNA has ribose.
2. Base pairs. DNA’s base pairs are C-G, A-T. RNA’s base pairs are C-G, A-U.
3. # of strands. DNA has two strands in a double helix configuration (H-bonds help to stabilize). RNA is single-stranded.
B. Function.
Nucleic acids are in genetic material like DNA and RNA.
Central Dogma.
As far as our understanding today, scientists believe that genes determine the sequence of mRNA which in turn determines the sequence of proteins.
https://www.khanacademy.org/science/biology/gene-expression-central-dogma/central-dogma-transcription/a/the-genetic-code-discovery-and-properties
Basic Steps: From Gene to the Primary Structure of Protein.
Step 1. Transcription.
In the nucleus, RNA polymerase unzips DNA and reads DNA in order to make and spit out pre-mRNA (transcribed from the DNA) using nucleoside triphosphates as building materials. Emphasis on triphosphates because the process requires lots of energy which is available in those phosphate bonds (e.g. each time phosphate gets cleaved).
Step 2. Editing the pre-mRNA.
In the nucleus, the pre-mRNA needs to be edited. A methylated structure called a “cap” is placed on pre-mRNA’s 5′ end. A poly-adenosine monophosphate tail is added at the 3′ end. Introns are spliced out leaving only the exons.
https://www.cell.com/trends/biochemical-sciences/fulltext/S0968-0004(19)30002-7
Step 3. Translation.
The “edited/fixed-up” mRNA is transported out of the nucleus and into the cytoplasm at the rough endoplasmic reticulum. The mRNA gets sandwiched between the large and small ribosomal subunits. The ribosome is the assembly site. The tRNA is the shuttle that pairs its anticodon to the codon on the mRNA and brings in the correct amino acid for assembly. As the ribosome moves along reading the mRNA, the protein strand that’s being formed (queue-fashioned) starts to stick out of the ribosome. This step is called “translation” because it’s like decoding a secret message on the mRNA to make the protein that you want.
https://www.khanacademy.org/science/biology/gene-expression-central-dogma/translation-polypeptides/v/translation-mrna-to-protein
See Appendix A Amino acid abbreviations; Appendix B Glucogenic, Ketogenic, and Glucoketogenic Amino acids; Appendix C 20 Amino Acids to Know Drawn at Physiological pH 7.4.
Appendix A. Amino acid abbreviations.
- Ala, Alanine, A
- Arg, Arginine, R (aRRRRRRRg arginine)
- Asn, Asparagine, N
- Asp, Aspartic acid, D (aspar-dic)
- Cys, Cysteine, C
- Glu, Glutamic acid, E (glue-EE the glutamic acid)
- Gln, Glutamine, Q (GQ guy got hot glutes)
- Gly, Glycine, G (Trivia: the achiral amino with an H sidechain)
- His, Histidine, H (Trivia: the pKa is so damn close to physiological 7.4)
- Ile, Isoleucine, I (iso-i or iso-eye)
- Leu, Leucine, L (leu-leu, loo-loo)
- Lys, Lysine, K
- Met, Methionine, M (methionine the meth head)
- Phe, Phenylalanine, F (fee-fye-fo-fum, says the giant in Jack in the Beanstalk)
- Pro, Proline, P (it get’s a p for just being weird and attaching to both the alpha carbon and amine, looks like an urinal…pee pee pee)
- Ser, Serine, S (reminds me of sarin gas)
- Thr, Threonine, T (three-o-nineTy time for pinty glug glug)
- Trp, Tryptophan, W (only cuz teacher said it looks like a W, the turkey amino)
- Tyr, Tyrosine, Y (looks Y-ish)
- Val, Valine, V (Val-in-tine’s day, V-day)
Appendix B. Glucogenic, Ketogenic, and Glucoketogenic Amino acids.
Ketogenic (LK): lysine, leucine.
Ketoglucogenic (ITFWY): isoleucine, threonine, phenylalanine, tryptophan, tyrosine.
Glucogenic: alanine, arginine, asparagine, aspartate, cysteine, glutamate, glutamine, glycine, histidine, methionine, proline, serine, valine.
Appendix C. 20 Amino Acids to Know Drawn at Physiological pH 7.4
Glycine
The only achiral amino acid because the sidechain is just a hydrogen.
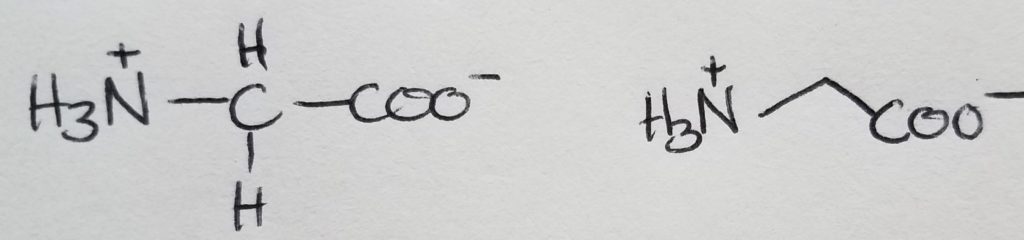
Alanine
The shortest sidechain, methyl group.
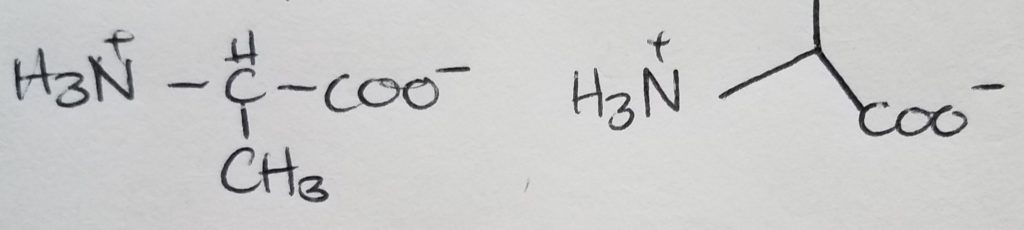
Valine
Looks like a short “V”.
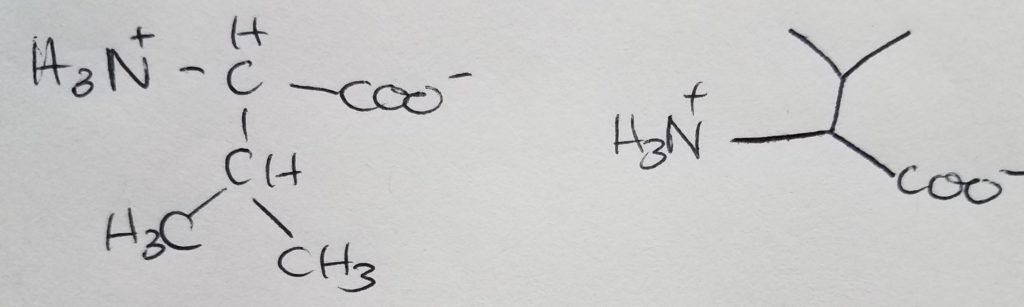
Isoleucine
Isomer of leucine.
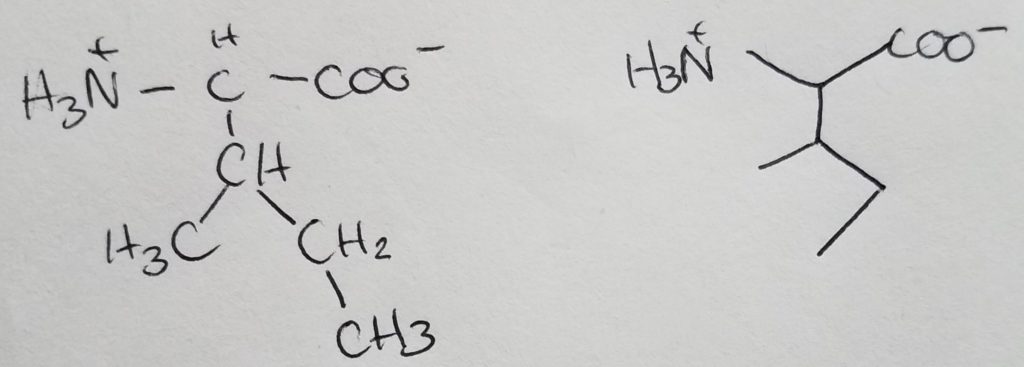
Leucine
Isomer of isoleucine.
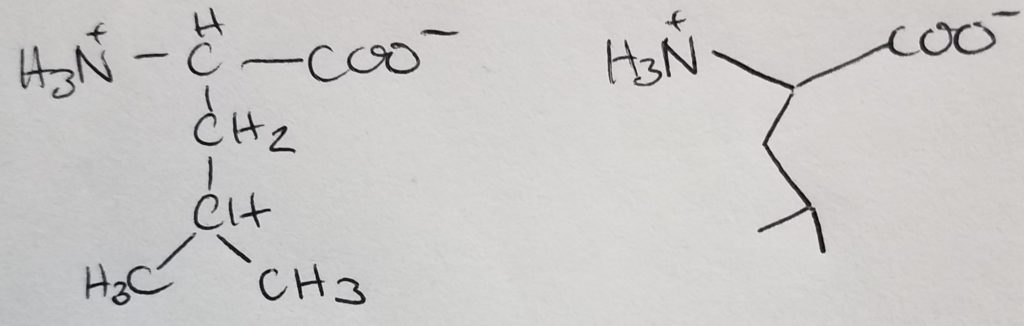
Resources.
References.
Bean, J. (2019). Amino.
Bean, J. (2019). Macromolecules.
Bean, J. (2019). Nucleotides and nucleic acids.
Bean, J. (2019). Protein structure.
Ferrier, D. (2017). Biochemistry (7th ed.). Philidelphia, PA: Lippincott Illustrated Reviews.
Bean, J. (2019). Nucleotides and nucleic acids.
Bean, J. (2019). Protein structure.
Ferrier, D. (2017). Biochemistry (7th ed.). Philidelphia, PA: Lippincott Illustrated Reviews.
Lieberman, M., & Peet, A. (2017). Marks’ basic medical biochemistry: A clinical approach(5th ed.). Philadelphia, PA: LWW.
